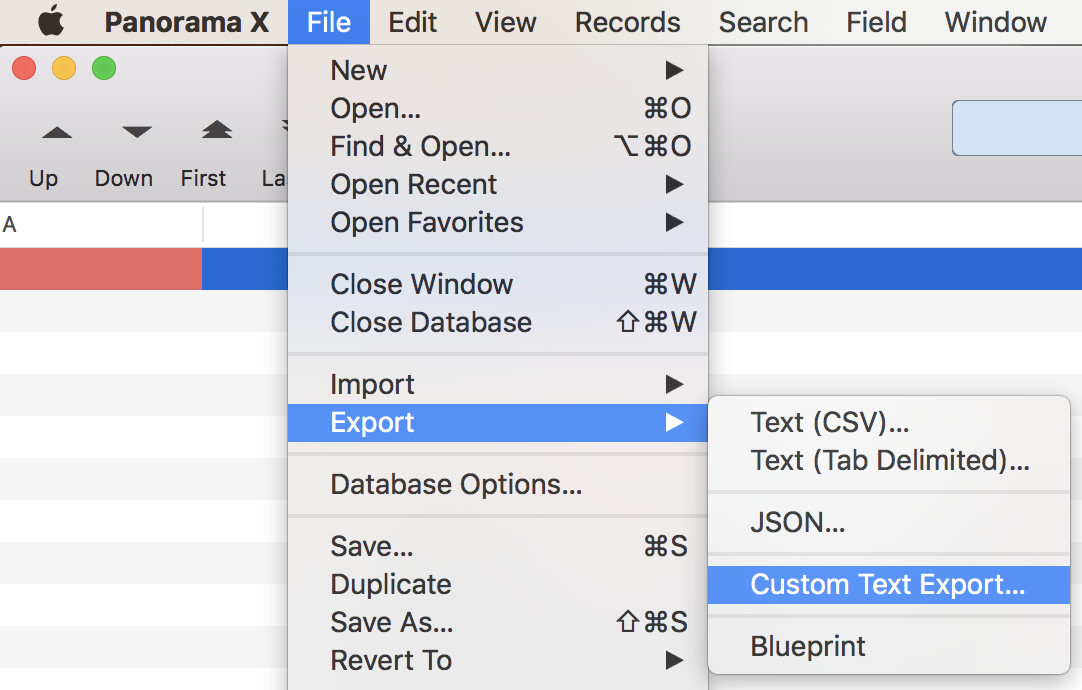
I’ve found directions that tell me to use File >Export > Text Export Wizard as a way to create a file of selected fields. Text Export
I don’t see that menu item in my copy of Panorama, 10.2.0.b38 (4460). I do see File > Export > Blueprint, but nothing happens when I choose that item.
What am I missing?
Do you know whether the rest of the information that’s included with the old ‘text export wizard’ directions still apply with the Custom Text Export menu selection?
I think you’re mostly right but my attempt to save the Export format as a template did not work, so perhaps there’s some change in that step.
Thanks for your help.
I followed the instructions in the Help, and my attempt was successful. What led you to believe your attempt was unsuccessful? If you go to use that template, you will need to click on the magnifying glass to get a menu of template names. You won’t see those names if you click anywhere else.
I can confirm that this is indeed the case. The only thing that changed was the menu item. Ironically, this was done to make it easier for new users, who often wouldn’t read the manual so wouldn’t know what a Text Export Wizard was. The documentation has now been updated to reflect the new menu item.
Yes, it’s taken me this long to get back to the topic. Thanks to all, especially Jim, who responded previously about where to find the menu item for text exports.
Of course now I have another question. I want to export text from fields where there are often commas and carriage returns within the text. Some tabs may also be within the text.
Is there a way to format the export from a field to keep the entire content intact? My intent is to open the text file with Word or Google Docs and convert the text to a table. In Word, that’s a simple operation when there’s simple data, but is challenging for longer text blocks.
Bernadette, in the olden days, we do a find and replace on those problem characters, changing them to something benign - like changing a comma to a # character. Then, after importing at the other end, we’d change the # back to a comma. Of course, that meant selecting substitution characters that didn’t appear in the actual content.
I guess the trick is - determine which character you want to keep as a delimiter, let’s say the comma, then substitute for the carriage returns and tabs. But the CR’s are also used to identify each record. So maybe only CR’s between quotes - depends on what the data looks like.
Chr(13) is a carriage return. You could also use cr() or ¶. Chr(10) is a line feed, which is used for the same purpose. A line feed could be also written as lf(). It’s likely that what you think are carriage returns are actually line feeds, and that’s why your replace function isn’t converting them.
You should export using CSV format. When you do that, Panorama will add quotes around any field that contains special characters. Then it’s up to the software you are importing into to recognize the quote characters and handle the text appropriately. I’m pretty sure the Word does that, probably Google Docs as well.
So far, the use of the replace formula in the custom export, with chr(10) replaced by “#”, and a tab-delimited file format, has worked best. I use an Advanced Find and Replace in Word to return the “#” instances to Manual line feed. That’s producing what I want. Thanks!
At some point, I’ll have a similar exercise. I’ll be pulling a text file off a webpage for import into PanX. From previous attempts, I’ve seen that line wraps activate a separate record. So a single CR (or whatever that character turns out to be) will need to become a space and two CRs in a row will need to become a single CR.
There may be some additional fussing around, but once the occasional zigs and zags are accounted for, it should be pretty reliable.
I’ve just used this process again, and I’ll share something I learned – maybe it will help someone else.
My custom export template converts line feeds, i.e. Chr(10), to “#” in two fields; I use tab-delimited format. I open the exported text file with Word and convert the whole file into a table. It worked previously but not this time.
I finally realized is that, in Word, I must create the table first, and only then convert “#” to manual line feeds. If I do the Replace operation before table creation, line feeds and paragraph marks both result in new rows in the table.
This is a familiar situation of needing to document the steps following the database operation. I may also experiment with further automation of sending the exported file directly to a Word template.
I tested Jim’s advice to use CSV format without applying any formulas to the fields being exported. It did not produce the result I wanted, but I don’t know why.
One export problem I haven’t solved. One record (of 70 total) produces a line of text with a dozen extra tabs following one field, and one extra tab after another field. I’ve edited the PanX record to make sure these aren’t accidental entries. Any suggestions?
Thanks for the suggestion. I gave it a try but the tabs still show up.
For now, I can delete the extra tabs before converting the exported text to a Word table. I’ll definitely keep an eye out for future instances of these extra tabs; there must be a reason they are being generated during export.
Based on your description there are definitely extra tabs in the fields. I’m not sure what you mean by “edited the PanX record to make sure these aren’t accidental entries”, but whatever you did did not work.
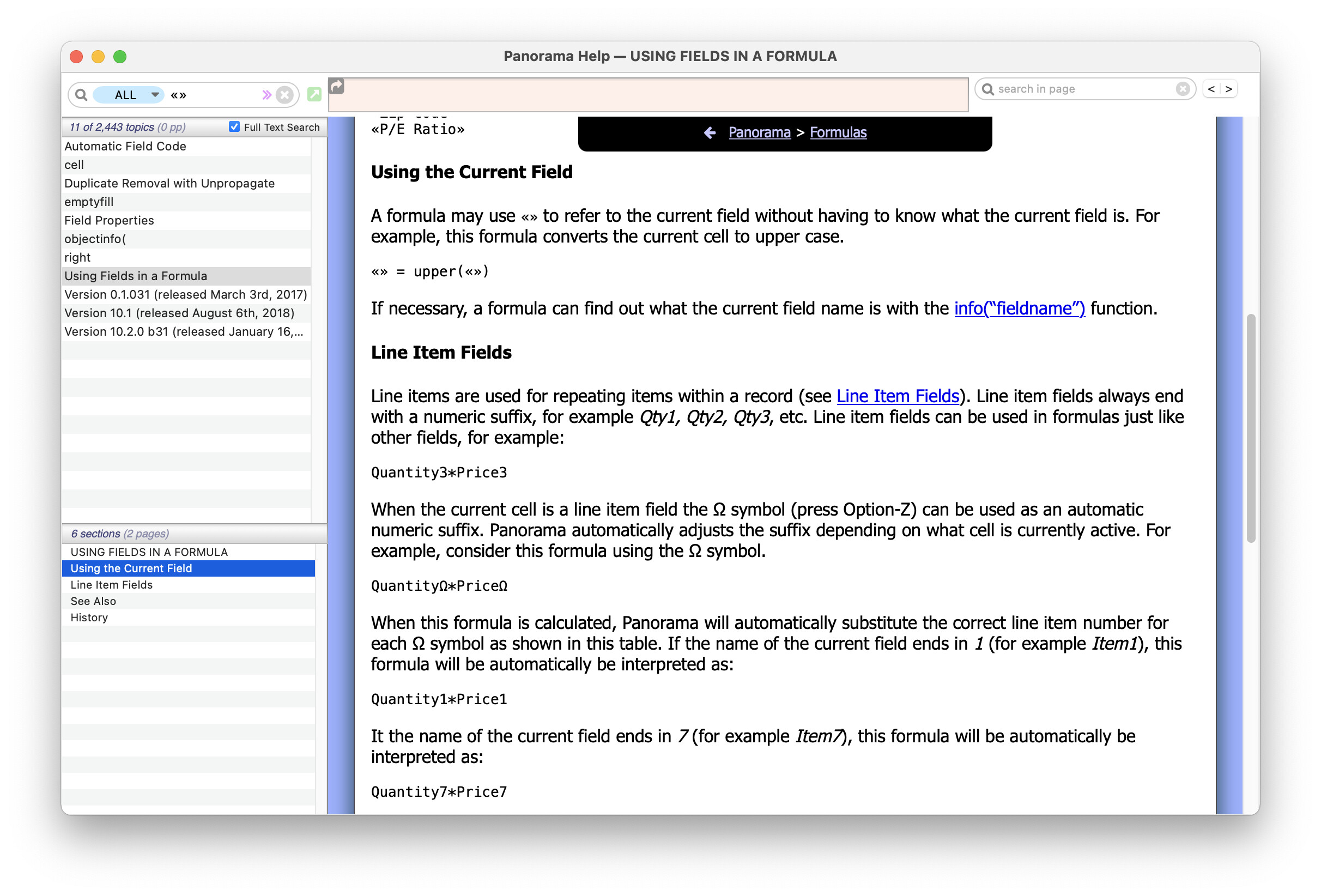
Here is a one line procedure that will remove any tabs from the currently selected cell.
«» = replace(«»,tab(),"")
This takes advantage of the fact that «» can be used to represent the current field.