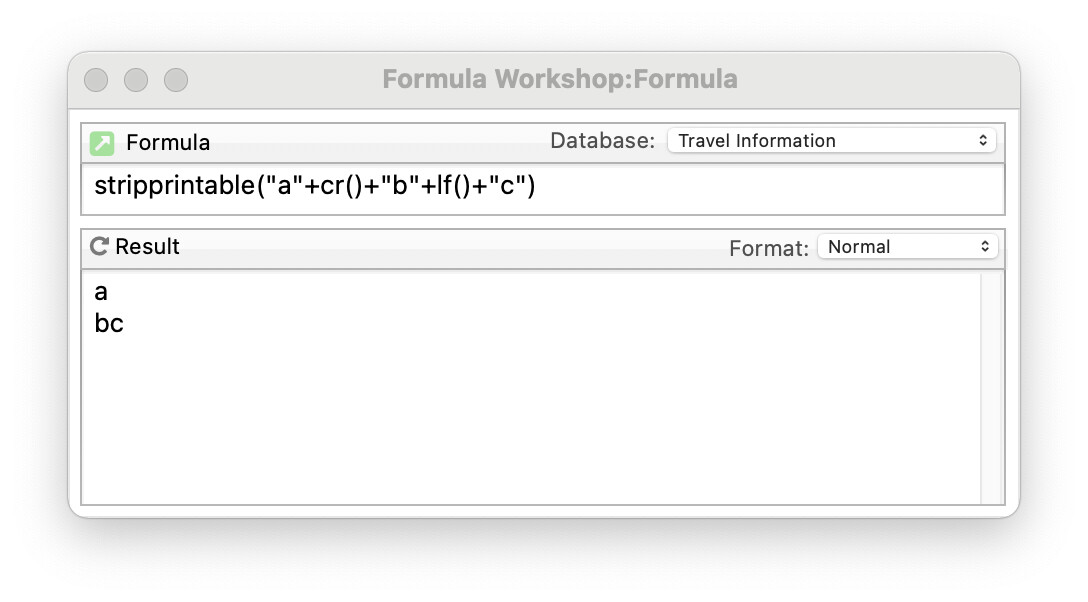
The documentation says that it doesn’t strip out spaces or carriage returns. If it doesn’t strip out carriage returns, I think it makes sense that it not strip out line feeds. I do think it should be stripping out your zero width space, and zero width non breaking space. Those wouldn’t have existed in the first place in Pan 6. I don’t know what third character you are referring to.
I tried the same formula in Pan 6. It strips out those characters. I agree about spaces and carriage returns. I take care of the carriage returns with another statement:
The stripprintable( function strips out all “control” characters (characters below 0x20) except for carriage returns. It also strips out all characters that Apple deems “illegal”. I do not know what characters are on Apple’s “illegal” list, and I suppose it could be different in different versions of macOS. As usual Apple’s documentation is pretty sparse.
The illustration below shows that this function DOES strip out line feeds but leaves in carriage returns.
I got that by opening your post for editing, and copying the text that you pasted, rather than Discourse’s rendering of that in the web page.
Somehow I missed the horizontal tab the first time I did this. That’s a control character, and stripprintable( does strip that. U+200B is the zero width space, and U+FEFF is the zero width no break space. Both of those are “legal” Unicode characters, or they wouldn’t have names.
I may have not made myself clear. In the following test string (Forget Pan 6) there are 3 unicode Ghost Characters.
U+A0
U+200B
U+FEFF
They are not visible.
Here is my new example:
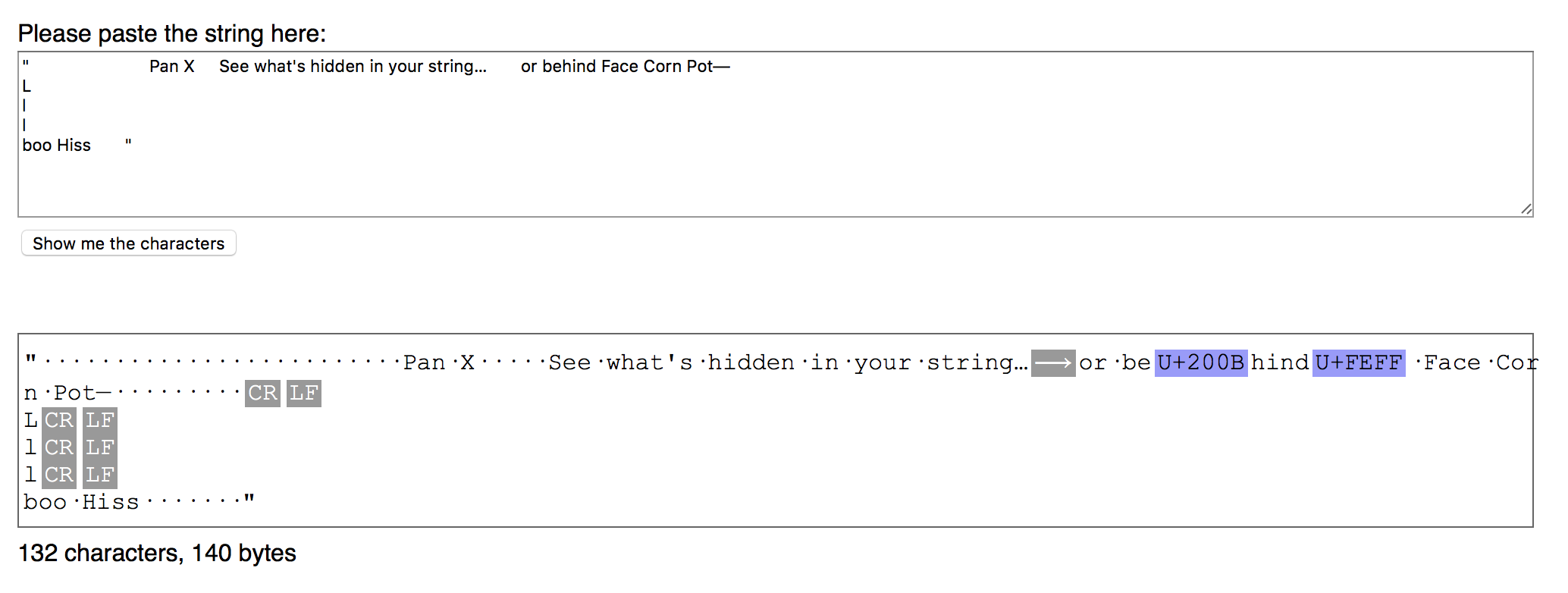
" <spaces this way—(U+A0) is before the next word that is see"See" what’s hidden in your string… "Tab to the left "or behind Carraiage Return Next-CRLF is next here>>>
after 3 carriage returns. U+200B is between “b” and “h” in the word “behind” above.
U+FEFF is right after “behind”. Three spaces here "
This is the showing of ghost characters from the URL: View non-printable unicode characters
This is the result before AND after stripprintable constains the same 3 Ghost Characters.
Actually the carriage returns are getting stripped also. Just not the Ghost Characters.
Jim Mentioned above that the carriage returns should not be stripped. They are.
My formula is:
«Result»=stripprintable(«Example»)
It is a one liner.
«Result»=stripprintable(«Example»)
Sorry if I was not clear before.
See the results of the link that shows ghost characters.
They are all valid, useful characters. U+A0 is the non-breakable space (which is clearly visible in your example, the same width as a normal space, U+20), U+200B and U+FEFF are the zero-width breakable and non-breakable spaces which, by definition, you won’t see, but they serve a purpose.
I think Jim’s point was that stripprintable( specifically strips characters U+0 to U+1F (what we used to call control characters) and also what Apple calls ‘values in the category of Non-Characters or that have not yet been defined in version 3.2 of the Unicode standard’. I’m not sure what it means by Non-Characters, but those three are all long-standing and useful Unicode characters which have existed in all versions of Unicode and I wouldn’t expect it to strip.
If you want a function to strip a wider range of characters it wouldn’t be hard to write, although it would be slower in operation.
I guess neither have I. I don’t care what some random Dutch web site says, I’m going to rely on Apple for a definition of what a legal character is. I explained what stripprintable( is designed to do, and it does exactly that. The three characters you mention are perfectly valid Unicode characters, they should not be stripped and they are not stripped.
I didn’t just mention it, I included a screen shot that clearly shows that they are not. You can easily duplicate those results yourself. Also, you seem to have missed my point that the text is changing in the copy/paste process.
Except for , there is no such thing as a “Unicode Ghost” character, I think you made up this term (couldn’t find it in google). A few Unicode characters do have zero width, but they are perfectly valid characters. If you want to explicitly remove these characters you would need to use the replace( function to do so, like this:
replace(sometext, chr(0x200B),"", chr(0xFEFF),"")
I didn’t replace the U+A0 character in this formula because that is NOT a zero width character – it looks just like a space but it does not act as a word break. But you could include that if you want.