I’ve just now changed this dialog so that you can click on the header dialog and select and copy the text.
However, the information in the header is really redundant – you don’t need it. All it is is the name of the current database, and the name of the database that is being linked to. The latter is already in the relation, it’s the DATABASE=... line. And the former is of course simply the current database.
Programmers have long wanted/needed better records of what they’ve done, so they invented what are called source control or version control systems (also known as SVN). There used to be several different SVN systems, but about 15 years ago a program called Git became the industry standard. By the way, Git is a free and open source program that was developed by Linus Torvalds. Linus is the inventor of Linux, and he wrote Git to keep changes to Linux organized (because he didn’t like any of the other SVN tools that were available at the time).
It’s far beyond what I can explain here, but Git can be used with Panorama. In fact, Git is the reason I developed Panorama’s blueprint system. All the other uses for blueprints are happy byproducts. Panorama X itself contains nearly 45,000 lines of Panorama code (in addition to 193,000 lines of Objective-C code), and I definitely needed to be able to keep track of when and how that code has been changed. That’s done by saving a blueprint whenever there’s been significant changes, and then “commiting” those changes into Git. Each change is accompanied by notes describing the change. (Note: When you save an overall database blueprint, with either File>Export>Blueprint or the View Organizer’s Database>Export Blueprints for this Database, ALL of the database structure is included, including field definitions, formulas, AND all relation definitions.)
Keeping a useful Git repository requires some discipline and organization. It’s definitely considerable extra work, though not too bad once you have it set up. For a large project, it’s essential to keep order from descending into chaos. If you ever wondered how I come up with the detail release notes for Panorama, basically I just go thru the commit notes that I put into Git since the last release.
Git is a huge topic, and one I’m not qualified to teach. I’ve learned enough to use it myself on one project. There are several full books on the topic, many YouTube videos, and tons of online material. Git itself is a shell program, but there are several GUI programs available that make it easier to work with. I’ve been using SourceTree for several years, but I’m considering switching to another one.
Most Panorama databases aren’t complicated enough to need to use Git, but it sounds like you might be headed in that direction. Something to consider.
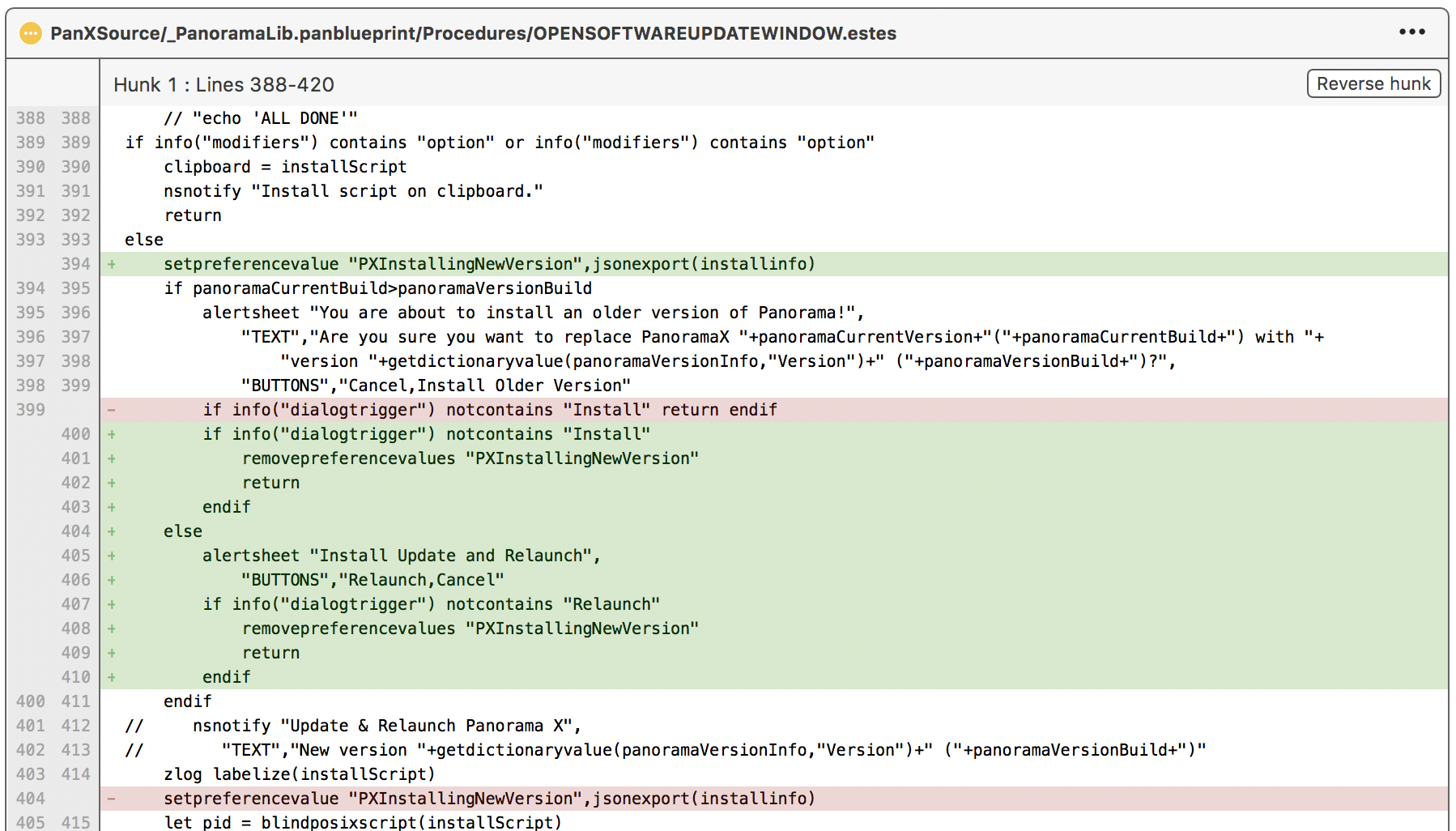
Here’s an example that shows you the type of record keeping that Git gives you. This is part of a recent change I made. The white background is code that didn’t change. Green is new code, and red is deleted code. As you can see, you can see exactly what changes were made as part of this update (this screenshot is from SourceTree).
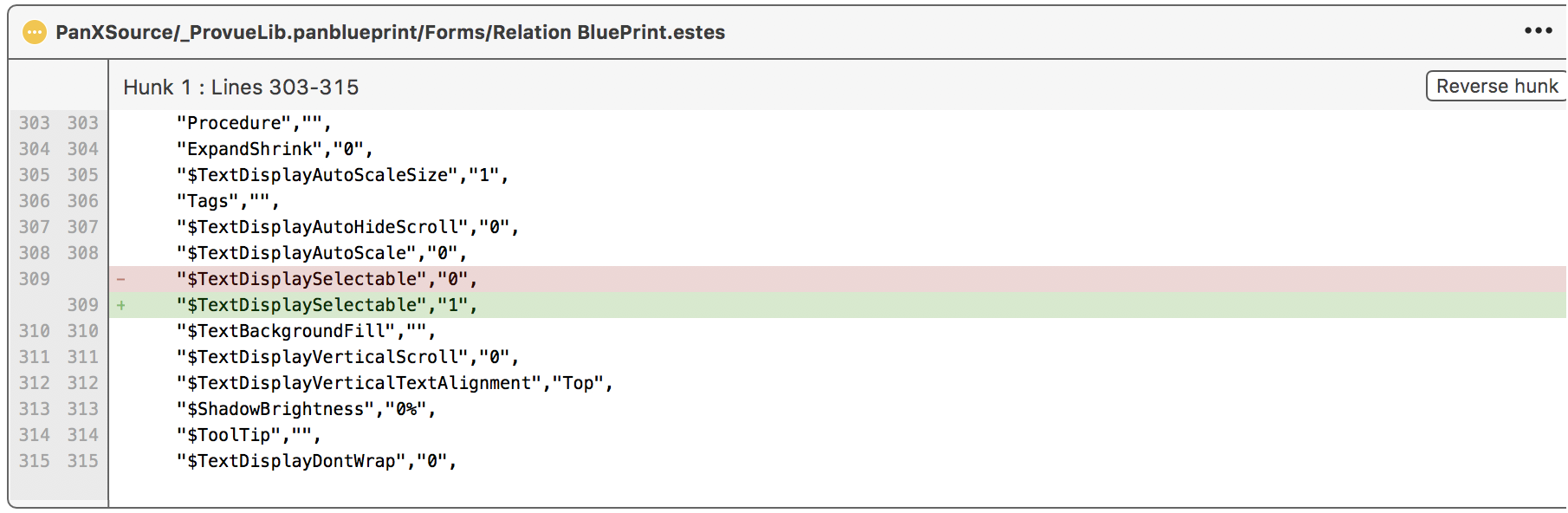
Blueprints allow even changes that are purely graphical to be tracked. Here’s the change I just made to allow the text in the Blueprint dialog header to be selected and copied. I checked the Allow Text Selection option for the Text Display object, and then saved the blueprint and committed the change.
As I mentioned, links are also included in the blueprint. Here’s part of the blueprint for a database with two links: