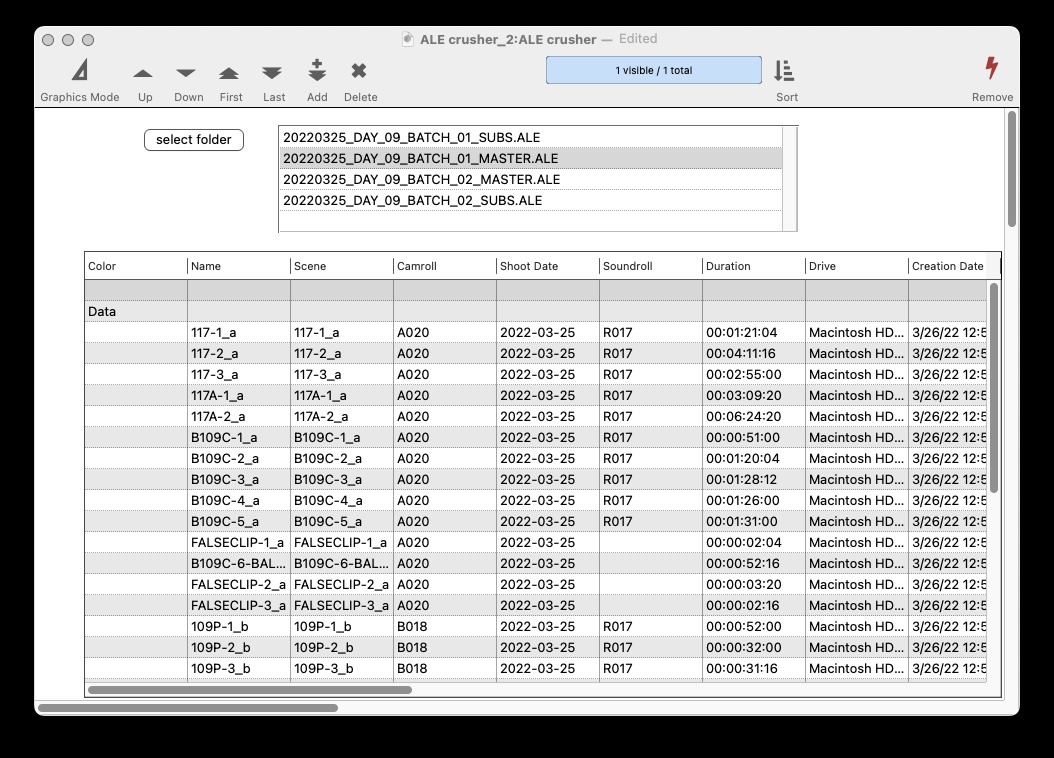
OK, first off, I cannot begin to describe how much i love the new Text List object - with just a scrawny bit of code I can load a tsv text file with a random number of fields and arbitrary text before the field headers and have it populate a text list, complete with column names and adjustable width:
If I click through the other files in the folder, I can verify that the fields are correct, because changes update automagically and manual adjustments to field widths are preserved. And none of these things affect the original file- its all in a variable! Stunningly great!
Here are two questions- Can i procedurally make some of those columns less wide? (some of the fields are useless to me, some of the time.) I know that i can eliminate data with an arrayfilter but given that i don’t necessarily know the field name/order, i don’t want to do anything i cant quickly undo in this preview window) Also, i know I can drag records up and down, but is there a way to manually drag columns into a new order?
ok sometimes “a couple” means three…
Now that importusing has left the building, it looks like importtext is the way to go, for semi-automatic text imports? I want to build a mini “import workshop” that will keep a persistent list of fields to rename or recalculate as i import them into my ‘complex database’. (all the list data in in a variable, at this stage of the pipeline)
Yes. Basically the importtext statement incorporates the functionality of importusing right into it. I wouldn’t say semi-automatic, I would say fully automatic.
Yes. All attributes of any graphic object can be procedurally modified with the changeobject statement. Really, when you change an object with the inspector panels, Panorama is essentially running the changeobject statement under the hood (actually it isn’t, but the inspector panels and changeobject share the same “under the hood” code). At any time you can view the object blueprint to see what code would be needed to procedureally generate this object.
Well, then you are better informed than I am. I am not aware of any such capability. Well, if you mean items in a text list, then yes, you can add code to do that.
Not really, but…
You know that the Import Workshop that comes with Panorama is just a Panorama database right? It’s not even locked down, so you can pick it apart to see how it was made. Warning – it’s complicated! But it does have a text list object that allows the columns to be dragged around, so it can be done. But it’s not just clicking a checkbox, a ton of code went into that.
I would start by making sure that the Text Import doesn’t already do what you need. It does have the ability to keep multiple persistent import configurations. And a cool trick that you may not be aware of – once you’ve set up an import configuration, not only can you use that in the Text Import window, you can use the procedure recorder to run an import and record it. It will record the code the Text Import window used, so then later you can “replay” it without even having to open the Text Import window. You’ll see that the code is an importtext statement with all of the rearranging code set up for you.