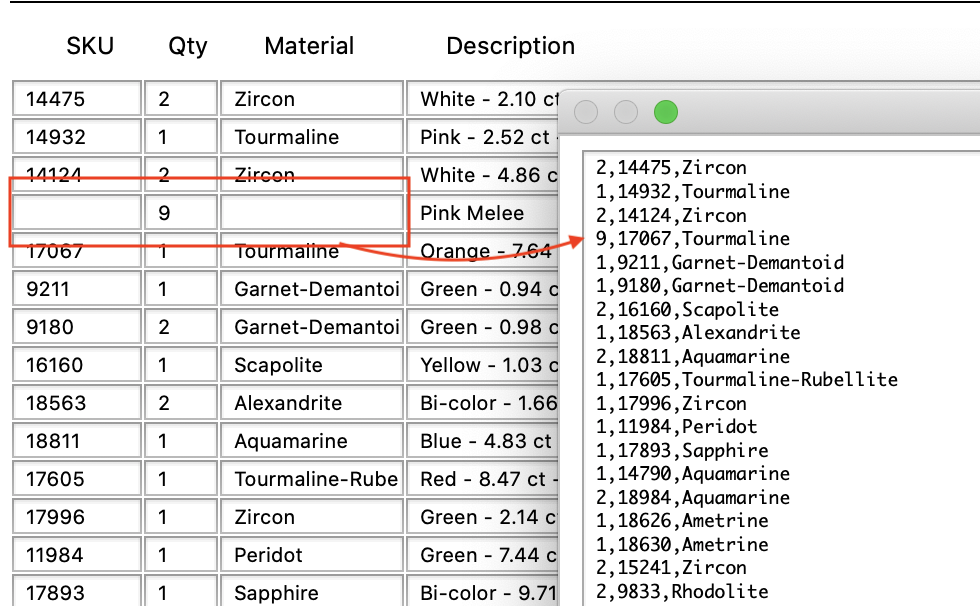
So it looks like lineitemarray does not add an empty element if the line item field is empty. It skips to the next line item, which gets everything out of sync.
I have noticed this occurring using the latest release of PanoX (10.2.x)
In the diagram, the red box shows a line item where “SKU4” and “Material4” are empty/blank.
(SKUΩ are all “Integers” and MaterialΩ are all “Text”)
The “DisplayData” on the right is the result of using ArrayMerge and LineItemArray … something like this:
Let aryItems=LineItemArray("QtyΩ",Chr(1))
Let t=LineItemArray("SKUΩ",Chr(1))
aryItems=ArrayMerge(aryItems,t,Chr(1),Chr(2))
t=LineItemArray("MaterialΩ",Chr(1))
aryItems=ArrayMerge(aryItems,t,Chr(1),Chr(2))
aryItems=Replace(Replace(aryItems,Chr(2),","),Chr(1),¶)
DisplayData aryItems
Am I doing something wrong here?
Is there a better/easier/more Panoramic way to create an array of all line items – ultimately to be used in a matrix display? (There are a total of 9 columns per row …)
Thanks!
– Mark
I think you could fill the empty cells with placeholder data before you build the arrays and then remove it in the finished array. That would cope with the problem that Bruce identified with the lineitemarray( function.
Cooper,
Thanks for the suggestion. That would work in this case.
That said, it seems to me the LineItemsArray should include all items and allow me to strip any out that I might not want. That is more consistent with the way other array statements and functions work.
Thanks,
– Mark
Apparently I completely missed this post back in 2018, sorry about that @BruceDeB.
This function is implemented as a custom function using this formula:
replace(arraystrip(arrayfilter(info("fields"),cr(),{?((import() regexmatchexact "^"+regexliteral(}+replace(quoted(tokenname(itemfield)),"Ω","")+{)+"[0-9]+$"), exportcell(import(),false()),"")}),cr()),cr(),thesep)
I think perhaps just changing arraystrip( to strip( would do the trick. But it’s 1 am, I think I’ll re-check my thoughts on this when I’m more awake. If anyone else wants to check my work on this, your feedback is welcome.
replace(strip(arrayfilter(info("fields"),cr(),{?((import() regexmatchexact "^"+regexliteral(}+replace(quoted(tokenname(itemfield)),"Ω","")+{)+"[0-9]+$"), exportcell(import(),false()),"")})),cr(),thesep)
1 Like
Thanks, Jim!
You’re thanking me too soon – that “fix” didn’t work.
No, not directly – but, you definitely gave enough breadcrumbs to work on it.
(but, if you have a solution ready-to-go, I’m all ears! LOL)
Please stand by…
Now you can thank me.
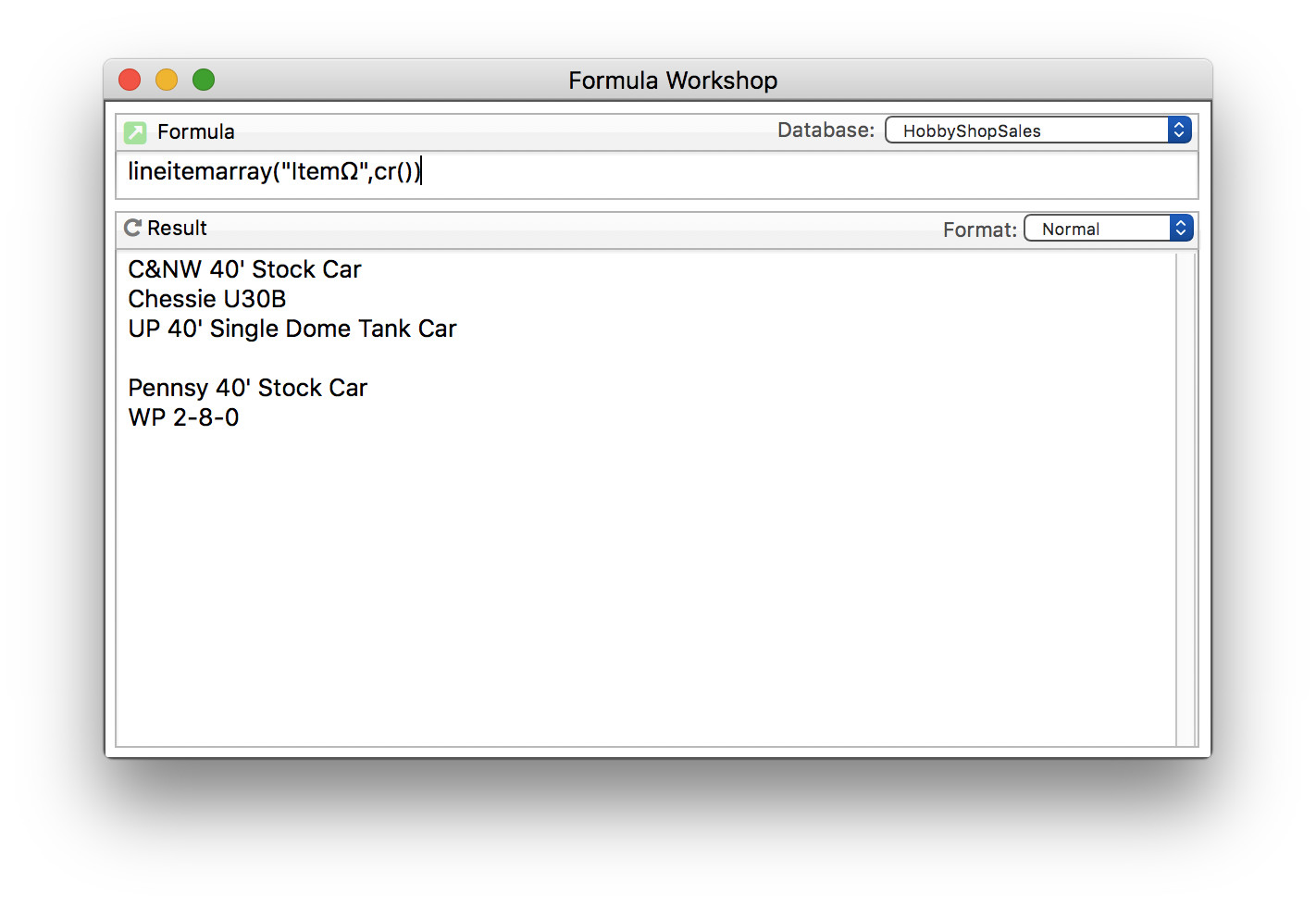
For grins, here’s the formula that works. This will be included in Panorama very soon.
replace(strip(arrayfilter(arraystrip(arrayfilter(dbinfo("lineitemfields",""),cr(),{?((import() regexmatchexact "^"+regexliteral(}+replace(quoted(tokenname(itemfieldname)),"Ω","")+{)+"[0-9]+$"),import(),"")}),cr()),cr(),{exportcell(import(),false())})),cr(),thesep)that works perfectly!
thanks (again), Jim, for taking the time to look at this.
– Mark
Funny thing is, I cannot remember how this came up originally. I must have had a workaround. Judging by the date, it must have been a schedule for my bocce league.
One thing to note: since you put “strip()” in there, it will strip off any empty first or last items in the list. To make this work for me, I had to remove the “strip()” function, and then it works well. The caveat is, it does not remove completely empty lines.
I guess the answer to that would be to first put in dummy items first and last, and then remove them afterwards.
As I said, it has been a while, so I do not remember much about this. The problem with the pandemic is that I have gotten involved in so many other things, and now that I am getting back to work, I have those other things taking up even more of my time.
Good point. Easy fix – this will strip blank lines on the end, but not at the start or middle.
replace(strip("!"+arrayfilter(arraystrip(arrayfilter(dbinfo("lineitemfields",""),cr(),{?((import() regexmatchexact "^"+regexliteral(}+replace(quoted(tokenname(itemfieldname)),"Ω","")+{)+"[0-9]+$"),import(),"")}),cr()),cr(),{exportcell(import(),false())}))[2,-1],cr(),thesep)For what it might be worth, here is the solution I came up with for implementing the lineitemarray( function.
arrayfilter(arraystrip(arrayfilter(dbinfo("lineitemfields",""),cr(),
{?(import() beginswith itemfieldname,import(),"")}),cr())
,cr(),{fieldvalue(import())})
This will include any empty fields in any position. Even if they are all empty you will still get an array returned with the proper number of empty elements. As i say, for what it’s worth.
1 Like
Using this formula you could confuse two different groups of line items with names that start with the same token value. If you replace this with this formula using a text funnel to remove the line item number from the end of the field name it should eliminate that possibility.
{?(import()[1,"≠-0-9"]=itemfieldname,import(),"")}