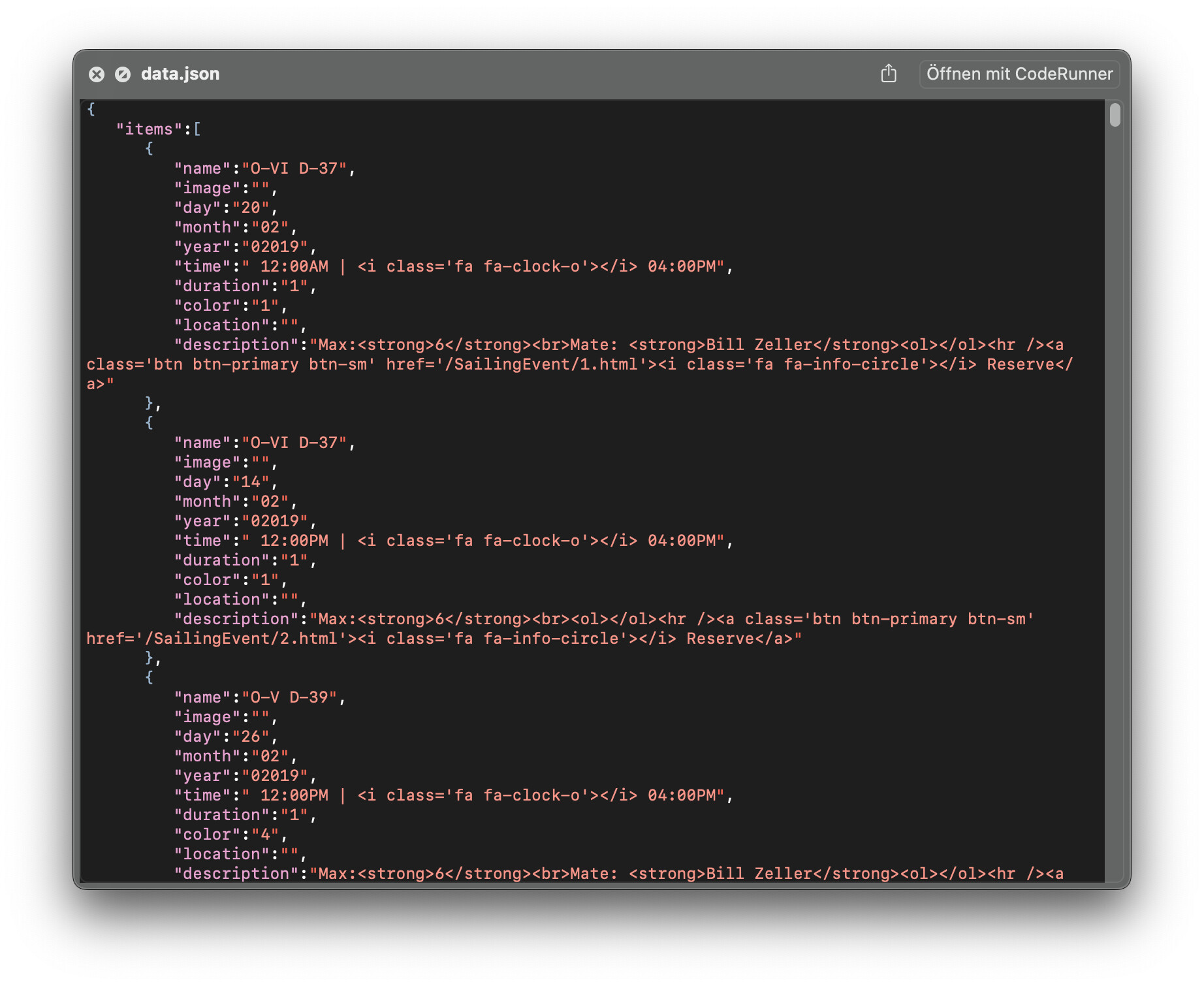
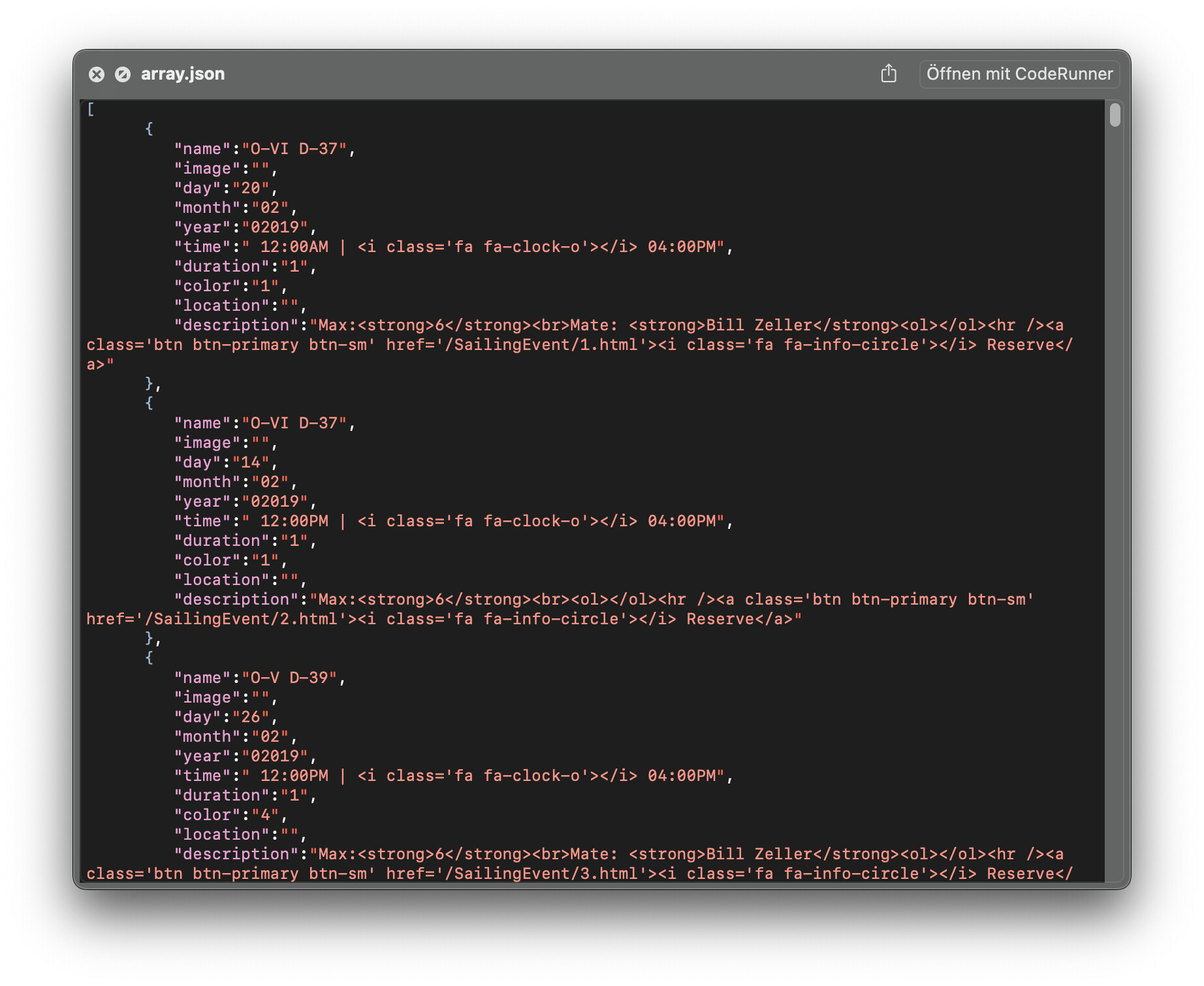
Thanks.
I had tried to import the 774MB file into a database and had to quit Panorama because my machine ran out of memory, which is why I tried to import it into a variable to see whether it was a valid structure. As Jim says, just because it’s a structure that can be held in a variable or binary data field doesn’t necessarily mean it can be imported automatically into a database. If the JSON has been exported from another flat-file form of data storage— a spreadsheet or a single row-and-column database — it might well be suitable, otherwise quite likely not.
These three records and four fields (named A, B, C, D) in a database
1A 1B 1C 1D
2A 2B 2C
3A 3B 3C 3D
might be encoded in CSV as
"A","B","C","D"
"1A","1B","1C","1D"
"2A","2B","2C",""
"3A","3B","3C","3D"
However, there’s a lot to go wrong with CSV/TSV — whether or not the first line contains field names, whether the separator is tab, comma or semi-colon, whether text fields are correctly quoted when necessary, whether real numbers use decimal point or comma, how tabs and/or newlines within fields are handled, etc.
In JSON it might be encoded as an array of three arrays:
[
[ "1A", "1B", "1C", "1D" ],
[ "2A", "2B", "2C" ],
[ "3A", "3B", "3C", "3D" ]
]
or, better, as an array of three dictionaries, in which the field names are the keys:
[
{
"A" : "1A",
"B" : "1B",
"C" : "1C",
"D" : "1D"
},
{
"A" : "2A",
"B" : "2B",
"C" : "2C"
},
{
"A" : "3A",
"B" : "3B",
"C" : "3C",
"D" : "3D"
}
]
That’s the least compact but least error-prone too. It’s the format that Panorama uses to export a database and it seems to be what it expects for import into a database too.
But even simple real-world data can’t always be forced into that row-and-column form… Take this file structure, five levels deep:
1 (folder)
1.1 (file)
1.2 (folder)
1.2.1 (file)
1.2.2 (folder)
1.2.2.1 (folder)
1.2.2.1.1 (file)
1.2.2.1.2 (file)
1.2.2.2 (file)
1.2.2.3 (file)
1.2.3 (file)
1.3 (file)
1.4 (folder)
1.4.1 (file)
1.4.2 (folder)
1.4.2.1 (file)
1.4.2.2 (file)
1.4.2.3 (file)
1.5 (folder)
1.5.1 (file)
i.e. a single folder containing five items, the second of which (1.2) is a folder containing three items, the second of which (1.2.2) is a folder, etc.
One way to represent that in JSON would be:
[
{
"type" : "folder", "name" : "1", "contents" :
[
{ "type" : "file", "name" : "1.1" },
{
"type" : "folder", "name" : "1.2", "contents" :
[
{ "type" : "file", "name" : "1.2.1" },
{
"type" : "folder", "name" : "1.2.2", "contents" :
[
{
"type" : "folder", "name" : "1.2.2.1", "contents" :
[
{ "type" : "file", "name" : "1.2.2.1.1" },
{ "type" : "file", "name" : "1.2.2.1.2" }
]
},
{ "type" : "file", "name" : "1.2.2.2" },
{ "type" : "file", "name" : "1.2.2.3" }
]
},
{ "type" : "file", "name" : "1.2.3" }
]
},
{ "type" : "file", "name" : "1.3" },
{
"type" : "folder", "name" : "1.4", "contents" :
[
{ "type" : "file", "name" : "1.4.1" },
{
"type" : "folder", "name" : "1.4.2", "contents" :
[
{ "type" : "file", "name" : "1.4.2.1" },
{ "type" : "file", "name" : "1.4.2.2" },
{ "type" : "file", "name" : "1.4.2.3" }
]
}
]
},
{
"type" : "folder", "name" : "1.5", "contents" :
{ "type" : "file", "name" : "1.5.1" }
}
]
}
]
If I use jsonimport( to import that JSON as a structure in a variable or binary data field, in this case called JSON, I can access its heirarchy directly:
getstructurevalue(JSON,1,"contents",2,"contents",2,"contents",1,"contents",2,"name")
==> 1.2.2.1.2
But how could Panorama know how to import that into a single database, a grid of records and fields, except as a single structure in a binary data field which is meaningless to me when I’m reading the data sheet? I can think of several ways to do it, but would need not only to know the structure of the JSON file but also to consider how I might want to display, edit and manipulate the data afterwards.