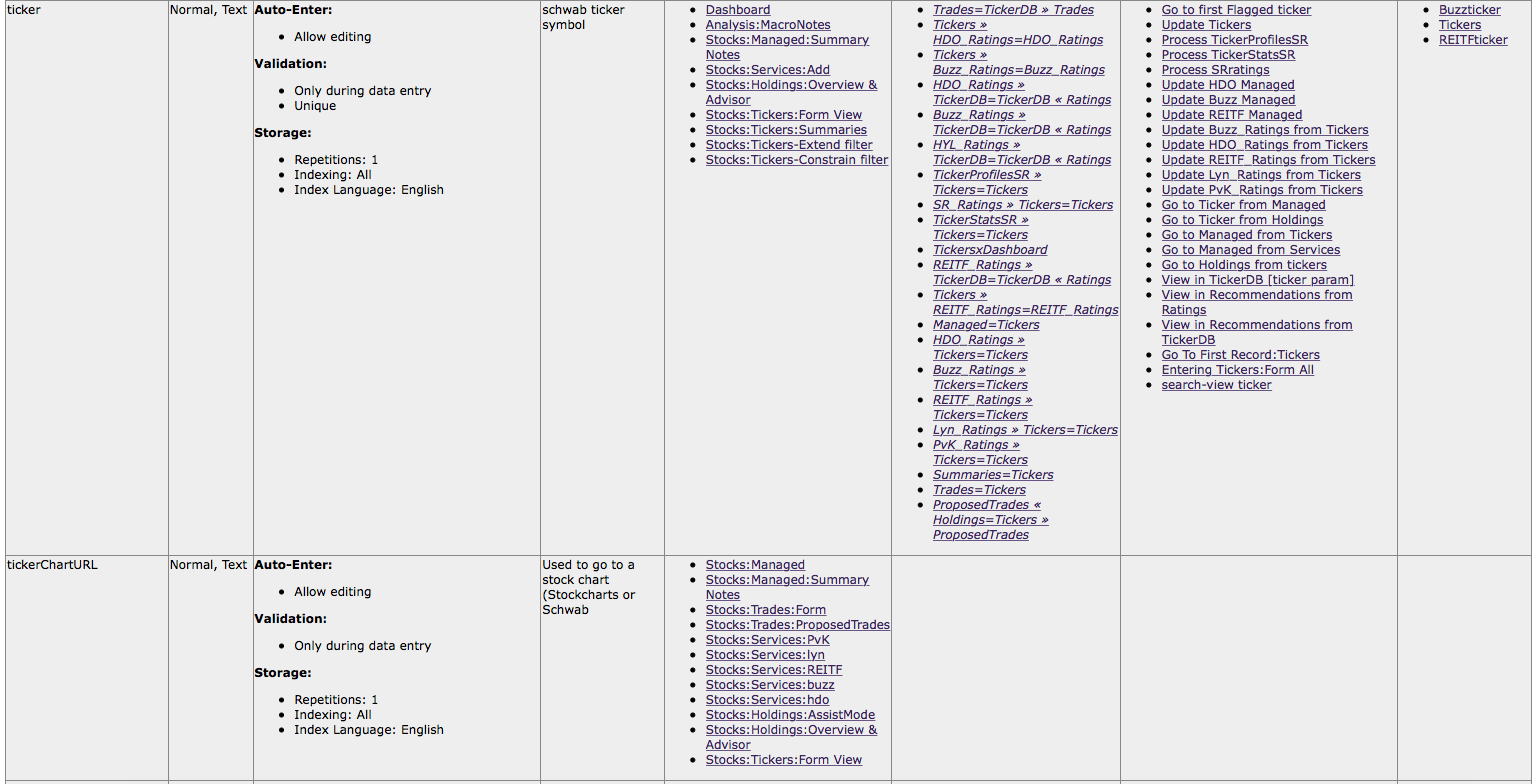
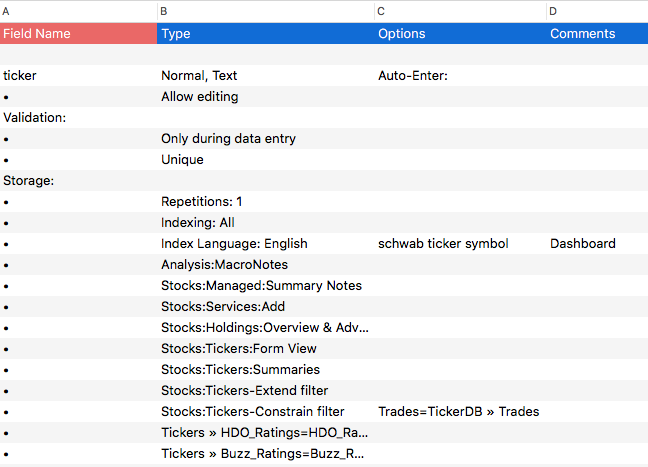
I want to import it into Panorama X. After some experimentation, the nearest I can get is to copy the data from HTML, paste it into MS Word, where it appears as a table, convert the table to text, copy the text, paste it into a plain-text TextEdit file (that’s quicker and easier than saving the Word file as text) and import it into Panorama X. I then get this:
which goes on forever. The carriage returns in the HTML field cause each of the elements in a field to create a new record in Panorama X.
The structure of the HTML file is quite rigid so I might be able to write code to untangle the data and put stuff where it belongs but it won’t be a trivial task and before I do that I want to check if any body has already cracked this coconut. Anybody?
It’s really weird the number of times I post a query to the forum and then come up with the answer - well, in this case, a better solution. Saving the HTML file in Page Source format makes the content much easier to untangle.
But if anybody has some further advice I open to hearing it.
Yes - I created a Web Browser Object (a feature I’ve never even looked at before today) and dragged the HTML file into it.
Now I want to get that data into the data sheet. I’ve searched the “web” entries in Help without finding what I want. The main focus seems to be on moving in the other direction. Is it possible to get the data into the data sheet?
And thanks James, I’ve used the tag functions before and they are truly wondrous but that’s a bigger task than I want to face right now.
That chart seems to be a rendering of the web page, and not the HTML.
That looks like financial information. I used to scrape web pages for stock information, but the pages kept changing until I could no longer scrape them. So now I use an API. It requires a subscription, but it is free for my modest set of data, and if you want more, the cost for individuals is modest. I am using iexcloud.io.
I am also using an API for Zip code information. Again, free for less than 250 lookups a month, which suits me.
I hate to ask this, but why would you want this information in the data sheet of a Panorama database? To me it doesn’t look like something that would be useful for sorting or searching.
If you do want to bring it into Panorama in some sort of structured way, I think James’s suggestion of using the various tag( functions is the only way to go, and it could be a somewhat major task. Though most likely that information is formatted with HTML
tags, so it might not be tooooo bad. But it would probably take hours, not minimutes.
In that case, why even get Safari involved? You can use Panorama’s fileload( function to read the HTML source directly from the index.html file.
Here are some thoughts about parsing your HTML file:
Read about Text Parsing and the many related functions and statements.
You are interested in the part of the HTML file included in table tags only. You could omit Word from your workflow, open the HTML file in TextEdit directly, and delete file contents (e.g. HTML header) outside of the table there. Or you use the PanX xtagvalue( function to extract only the part that is located between table tags.
For sure, you should replace all line breaks with vertical tabs — except those after closing tablerow tags. So you can avoid that big amount on records and keep your table rows together.
If you use the direct import into PanX, you have to consider replacing the combination closing tablecolumn tag + tablecolumn tag with a tab, too.
All that parsing — once it is working — could be done during the import already with the importtext option “REARRANGE”.
With the web browser object, you IMHO have what you want already: You have access to all the data, keep the original table layout, and you have all links clickable. — But you decide if you want to do additional parsing work.
Thanks Kurt but every tag is in a new record rather than in strings. I doubt that I’ll have to do this again so I’m happy to have extracted all of the data I want in my own less elegant way - I got 4500 records down to 800 fairly easily. Job done.