Greetings. One of the things that still has not been implemented is to not allow a duplicate entry. It seems after two years of Pan X this would have been implemented. There have been many additions and procedures that have been added, but to not have a “basic” that used to work in Pan 6 is not good.
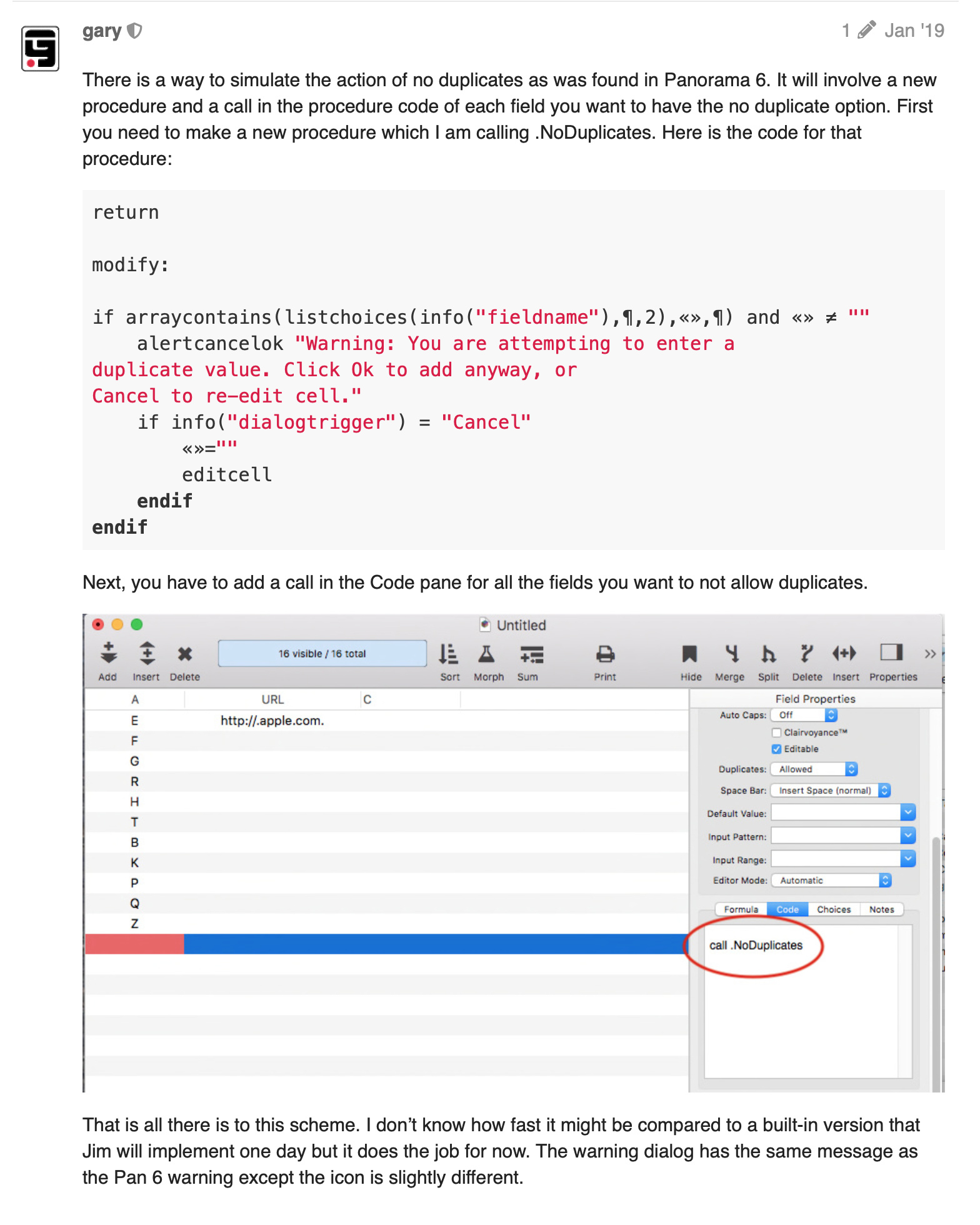
There is a way to simulate the action of no duplicates as was found in Panorama 6. It will involve a new procedure and a call in the procedure code of each field you want to have the no duplicate option. First you need to make a new procedure which I am calling .NoDuplicates. Here is the code for that procedure:
return
modify:
if arraycontains(listchoices(info("fieldname"),¶,2),«»,¶) and «» ≠ ""
alertcancelok "Warning: You are attempting to enter a
duplicate value. Click Ok to add anyway, or
Cancel to re-edit cell."
if info("dialogtrigger") = "Cancel"
«»=""
editcell
endif
endif
Next, you have to add a call in the Code pane for all the fields you want to not allow duplicates.
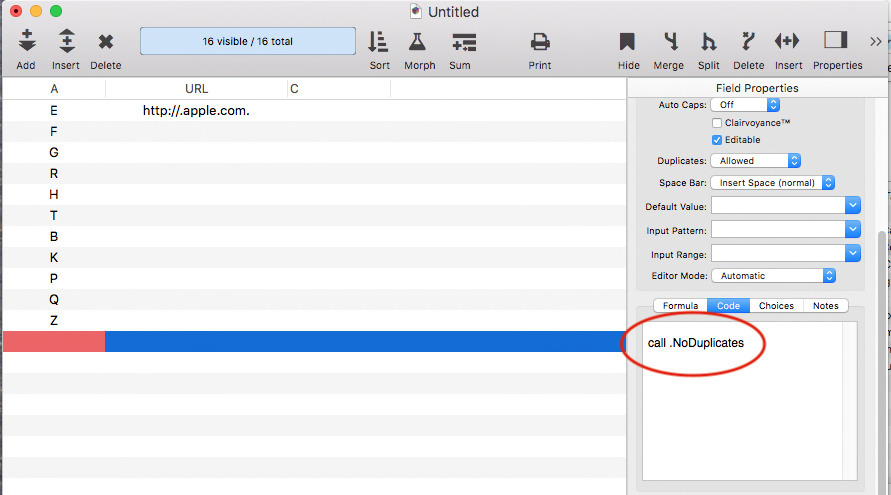
That is all there is to this scheme. I don’t know how fast it might be compared to a built-in version that Jim will implement one day but it does the job for now. The warning dialog has the same message as the Pan 6 warning except the icon is slightly different.
Thank you. I will give it a try.
Just a note to point out that the procedure code was originally missing the leading return statement that got lopped off when I first pasted it in. I have since edited the code and it should now be correct as shown above.
Worked like a charm. Thanks again Gary
It works, too, without the return statement. What is the sense of it?
It is what the Help file indicated should be used. Other than that, I really don’t know.
Here it does not work, if I add the return statement.
Do you by any chance also have a return in the field Code pane as well? If I put one there in addition to the one in the called procedure it will work for me either.
In the example in the Help file, there was other code above with a click: label. The Return is there to keep that code from continuing on through the modify: code.
Panorama X 10.2 introduced some significant improvements to automatic field code, now allowing you to run different code when different actions occur, for example code run when the field is clicked, vs. code run when the field is actually modified. To do this, you must add specific labels to the code, for example click: or modify:. If those labels are present, the code doesn’t run from the top of the procedure, as it normally does, instead, it starts running from the label.
In previous versions of Panorama, the automatic field code would only run when editing was finished and the field had just been modified, and the code would always run from the top. If you leave out the labels, it will still work that way. In this particular example, modification is the only action that you have written code for, so you could leave out the initial return statement and the modify: label, and just start with the first line of code (in this case if arraycontains…).
This special behavior (starting at the label instead of at the top of the code) only happens in special circustances, specifically, only if the code is in the Code panel of a field – OR if the Code panel calls this procedure and does nothing else. If there was any other code in the Code panel besides the call statement, it would not jump to click: or modify:, but start at the top of the .NoDuplicates procedure (if there is more than one line of code in the Code panel then the special labels must be put in the Code panel itself, not in a subroutine).
So, if the .NoDuplicates procedure is called from somewhere other than the Code panel, the code will start running from the top. In your example that is probably never happening, so that initial return statement isn’t coming into play. But if that ever happened by accident, you might want to handle that situation. By putting a return statement at the top, you make sure that the code doesn’t fall thru and run your modify: code. Or, if you did want that code to run, you could leave out the return statement. Or you could put some different code at the top of the procedure and a return statement, to perform some different action in that case.
Personally I think it is usually a good idea to put a return statement on the top in this situation, just in case this procedure gets called in some way I wasn’t expected. That insures that nothing happens in that case. Or, since modify: is the only action being handled by this particular action, you could just leave out the return and the modify: label and let it work the way it did in previous versions of Panorama.
I don’t suppose you are running Panorama X 10.1 or earlier? It would have to be either that, or you left off the modify: label.
Hmmm, it seems that No Unique is also not working. The documentation shows the Duplicates option for Field Properties in the illustration but never mentions the three choices.
As of Feb 16, this issue was marked resolved, so it should be fixed in the next release.
I’ve been a loyal Panorama user since my very first Mac database roughly 20 years ago. Sadly, I’ve decided it’s time to move on.
I use my database to store a list of vinyl record albums that I sell on various websites. I have roughly 60,000 unique entries, with more added daily. My database only has 8 fields.
The reason I originally used it were:
- Speed
- Native Mac application
- Ability to notify me when the most crucial field (the unique “item number” for each entry) was accidentally duplicated.
With Panorama X’s inability to return the duplication warning function, and it’s slow response when I’m entering new items, there is absolutely no reason to continue to pay a premium for a program that I can much more easily implement using Excel.
I hate doing this. I’m a Mac dude through and through. Cut me, I bleed Apple Juice.
But this is no longer tolerable.
Bye Bye.
Mikel
You are correct. There is no duplication warning in Pan X. I had the same problem because I used to have that in Pan 6. I posted that same question of one of the Pan X gurus gave me a workaround that worked perfectly. I too am frustrated that Pan X is missing some functionality that I used frequently in Pan 6. I am not too interested in the scientific procedures. Hopefully, Jim will be able to bring some of these everyday items we use back to Pan X.
- If you had read this thread before you would have seen the information that the “No Duplicates” issue is solved already and will be part of the next update version.
- If I remember correctly, Excel is commercial software, too. And I am not quite sure which subscription price is cheaper. (In fact, I am pretty sure.)
- If you are really able to implement the “No Duplicates”-feature in Excel in a more comfortable way than is possible in Panorama X already now using Gary’s workaround, I invite you to teach that Excel technique to me — and I am not too bad in Excel. Filtering and searching duplicates after you have entered new data is not the same what you are asking for here. (And that could easily be done in Panorama X as well.)
I have used a slightly different strategy to avoid duplicates where users are entering a value. I prompt the user for the data with a GetText, or similar, statement, then test to see if the value is already present before adding a new record with that data; testing is done with an aggregate statement. I was not satisfied with leaving the user with an option to accept the duplicate; I wanted to prevent it in all cases.