Squirrel,
If you set up a dictionary of the country codes and their expanded names you will have a lot of versatility. So if you don’t know how to do that, it’s a really valuable lesson/exercise because the technique you will learn will help you in many future projects.
I can imagine a situation where you don’t need to fill a field with the expanded name at all - because you can use the country code to display the expanded name on the fly.
For example, if your dictionary was called countrycodename where each element had the code (US) for the key and the full name (United States) as the value, and you had a specific code in a variable ccode, then
getdictionaryvalue(countrycodename,code) would display the country name if it were in the formula of some display object. Something like that. I might be a little off; still learning myself.
I know that’s not what you are asking to do. Just letting you know the potential.
Others can be more specific. For now, a starting place is to look at Data Dictionaries in the Help (All Categories)
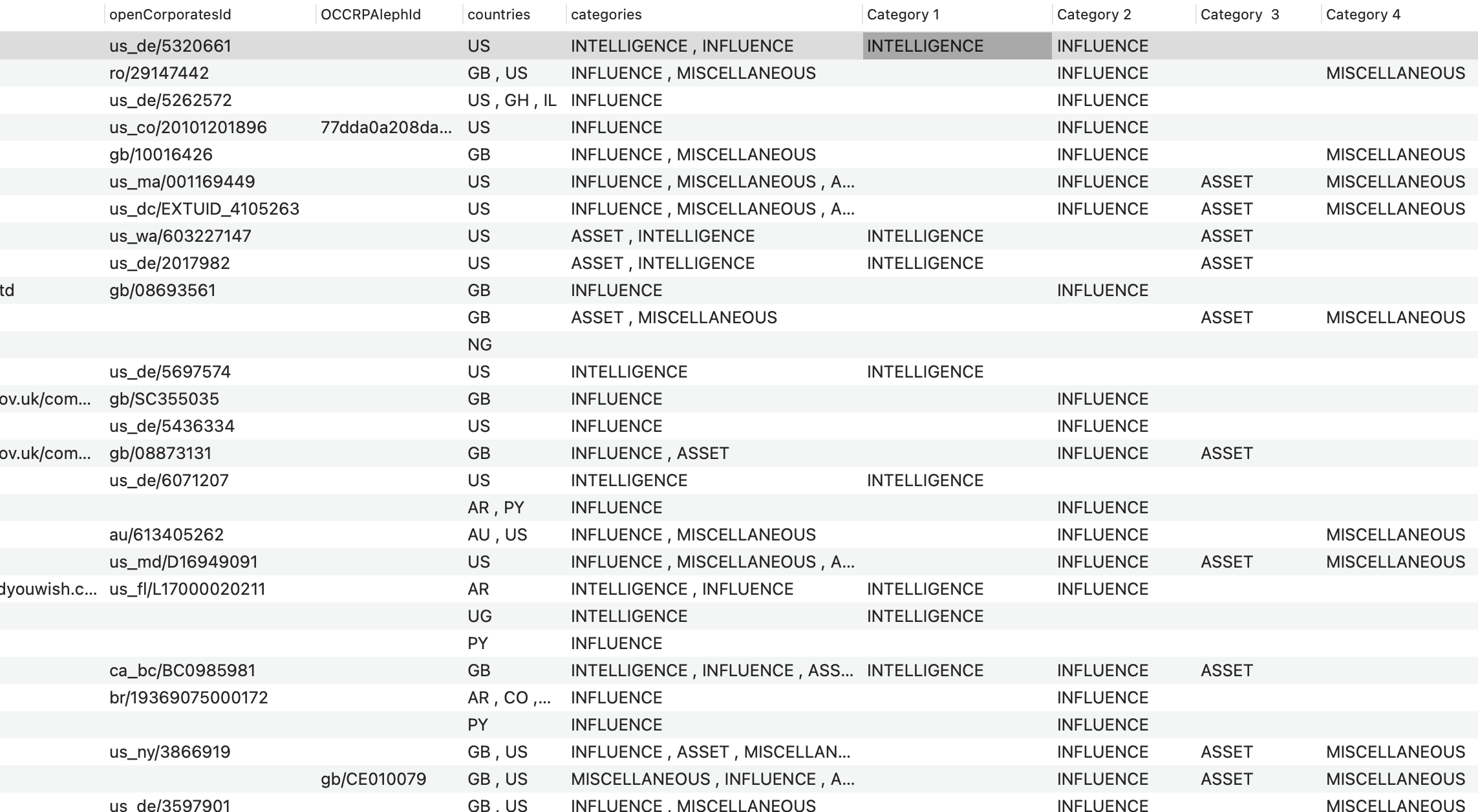
Note that Jim’s example used a maximum of 6 codes in a field for an example. So in addition to taking a little time to be familiar with dictionaries, it would be handy to have a procedure that told you the maximum number of expanded name fields you’ll need before hand and set them up first. We (forum members) can help with that too.
However, there is very little overhead penalty to have extra fields that are empty. So you could create more expanded fields greater than you’ll ever need. The unused one won’t “cost” very much - though for me, those extra fields would be like fingernails on the blackboard - just a generational thing; like worrying about the cost/duration of a long-distance call to Canada.
Finally, though a dictionary is one structure to hold a code/name pair, it is also possible to do the whole thing in an array structure with array-type commands.
What if you keep the Country field, but modify its content so you have both a code and its full name in the field - separated by a space? If you have more than one code, you’d have codename then carriage return and code2name2, etc.
The single field would show just the code and name. When there is more than one code, you’d have a separate line in the same field for each code/name pair. The code and name are separated by a space and the different code name pairs are separated by a carriage return.
If you need to strip off either the code of full name (which could have spaces), that would be easy using a text funnel.
The code would be myfield[1," "][1,-2]
The first bracket gives everything up to and including the first space - that would be the code and space, the second bracket gives everything up to the penultimate character - dropping off the space at the end.
and the name would be myfield[" ",-1[2,-1]
The first bracket gives everything from the first space to the end. The second bracket gives everything from the second character to the end of the string - dropping off the leading space.
The kids these days use fancy “regular expressions” for that kind of thing. The old-time-y text funnels are my jam.
That’s for a single code/name pair, with multiple code/names in the field it gets more … interesting.
Let’s see, I don’t want to introduce a gruesome image of pussy cats. There are a lot of ways to pluck leaves from an artichoke in PanX.