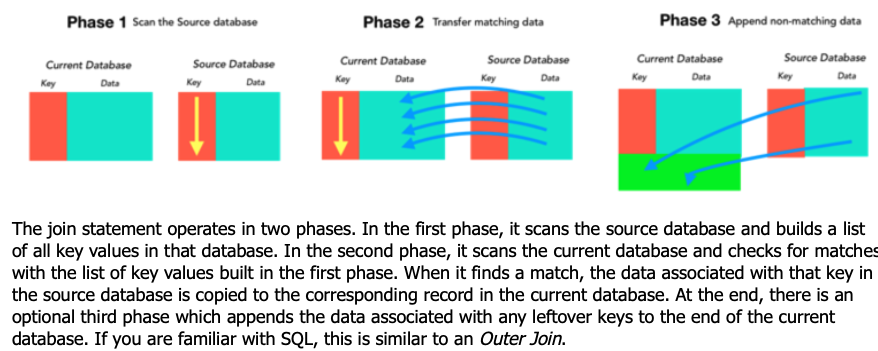
Db 2- CMS Drug and Therapeutic Class Crosswalk (“CMS crosswalk”) contains the RxDC drug code and therapeutic class code for each NDC and other fields.- 176,551 rows
the CMS Drug and Therapeutic Class Crosswalk is public domain at https://www.cms.gov/CCIIO/Programs-and- Initiatives/Other-Insurance-Protections/Prescription-Drug-Data-Collection
see:
Primary Filing Resources - and download: RxDC drug name and therapeutic class crosswalk (XLSX)
I would like to achieve the following: (do not wish to match these manually)
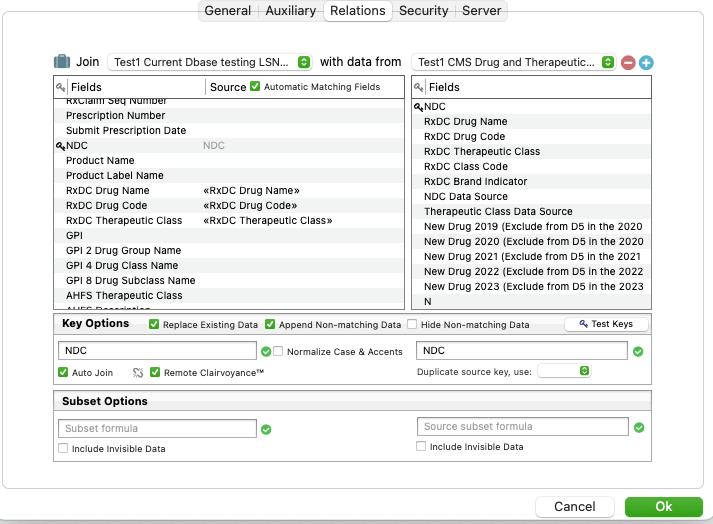
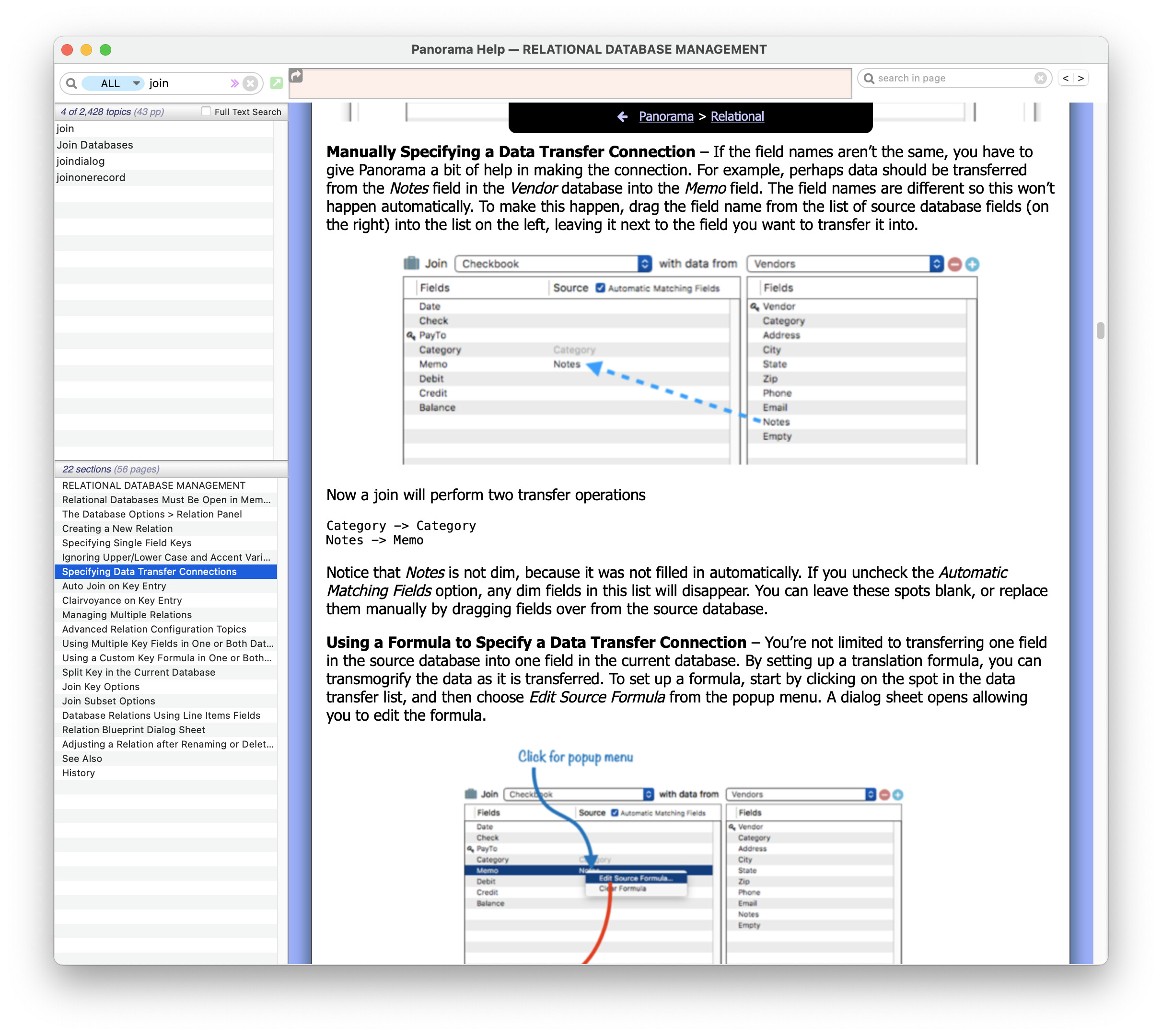
using the NDC codes in Db1, I want to import the corresponding information from Db2 into the same row as each unique NDC in Db1. the new column headings (Field names) can be inserted next to the NDC field name or at the end of the existing NDC code row in Db1.
however, my result did not succeed. So I created 2 test databases, went through the process and joined the databases, but it did not result in what I wanted/needed.
the first time it did nothing, so I took the current database and added the fields from the source database that I need to have in the current database: RxDC Drug Name, RxDC Drug Code, RxDC Therapeutic Class
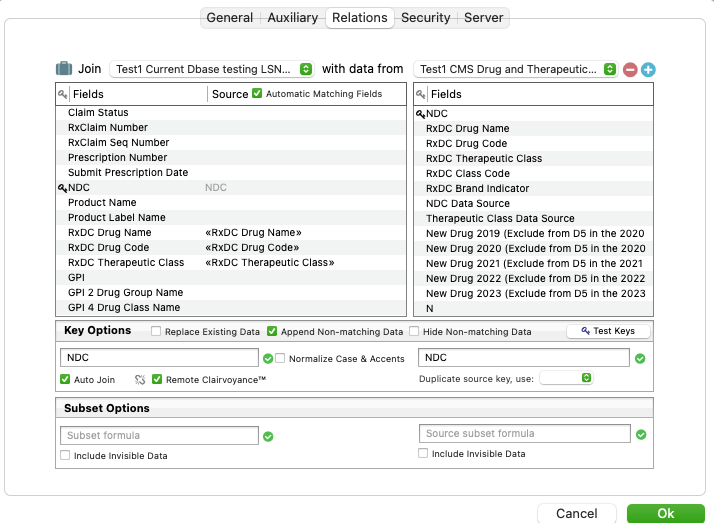
I reattempted the join:
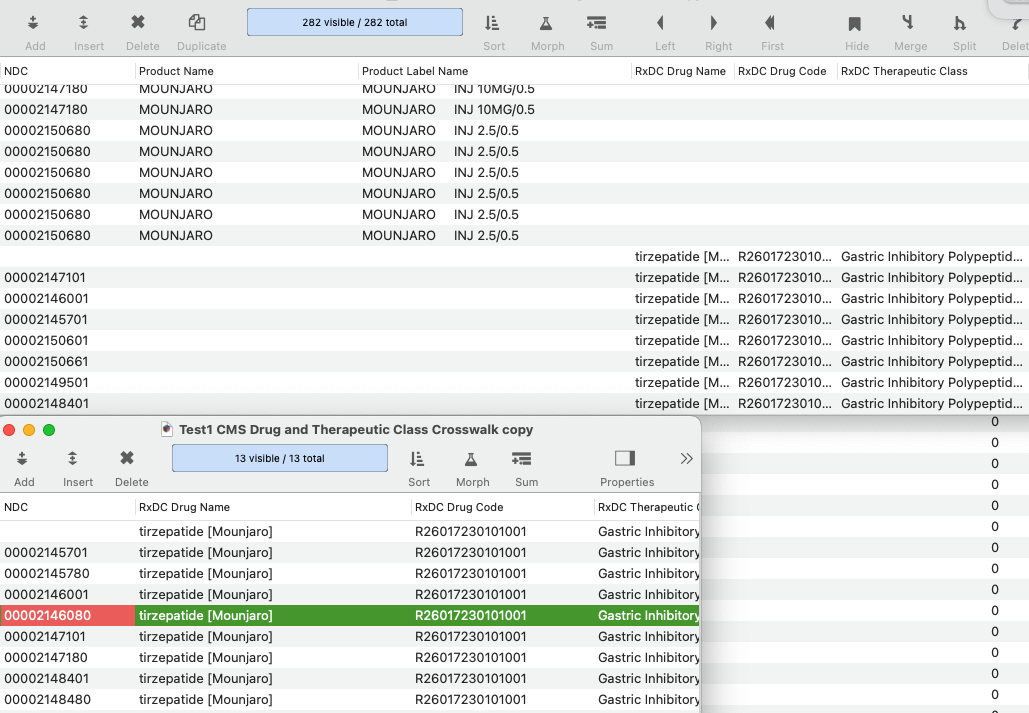
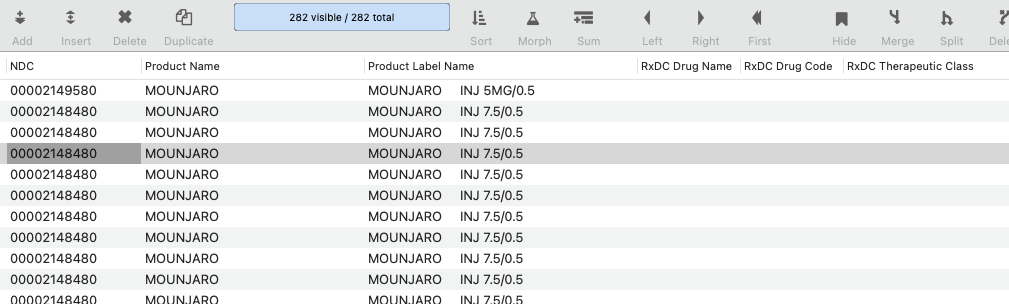
it looks like it appended the database and created from 272 records to 282 records.
but it did not take NDC 00002148480 and add: tirzepatide [Mounjaro], R26017230101001, and Gastric Inhibitory Polypeptide Analog to the current database fields, where those cells are all blank
It looks like you are setting up the relation correctly, as far as I can see. So if some data values aren’t working, there must be errors in the data. The matches must be exact, including any leading or trailing spaces. I suspect that you have typos (probably extra spaces) in either your data or in the data downloaded from the cms.gov website.
Hi Jim, thanks for the look and reply. you have me thinking that if I am matching on the NDCs in the current and source databases, and the NDCs are from different databases, they may not be seeing the leading zeros (or there are typos) as the same number even though when I look at the screen they “look” the same. will check on that. I will make sure they are the same field type: number (integer or float) but seems like Text field should work.
Eureka… was able to get it to work. played around with a few combinations in the test database and got it to work and was able to replicate it with linking the 176K codes to the 11K primary database.
the difference was checking Replace Existing Data. previously was ONLY using Append Non-matching Data as I did not want to ‘replace’ the reference NDC codes I was matching against. (unrealistic paranoia I suppose).
If you only have Append checked, you are not doing a Join (but are doing an Append).
Left Join = Replace checked
Outer Join = Replace & Append checked
Inner Join = Replace & Hide checked
I would also take a look at the source fields on Current side of the Relations panel as they should be dimmed and they are not (in your screenshot.) Something is going on there.
They will be dimmed if they have been automatically filled in by Panorama, but they are not dim if they have been manually dragged into place. So I think he is fine, he just manually dragged the fields over, not a problem.
My experience has been that even after I have unchecked the Automatic Matching Fields checkbox, that Panorama continues to automatically match fields if I add new fields in the Current db, that do match the Source db, but were not previously part of the Current db.
I also have found that If I have a non-dimmed match due to a difference in spelling of two common fields, that when I adjust the spelling, the field name that was once not dimmed, then becomes dimmed.
Panorama seems to really want fields to be dimmed and that trait seems to be Panorama’s preference. Thus seeing matching field names not being dimmed is something that I have not been able to accomplish when the names are identical.
Hey John, once you got the fields and settings figured out, how long did it take Panorama X to fill in what you wanted? One database had 10K records and the other 176K records, right?
because I am incapable of short answers…
the beauty lies in the request from Pan X: task was to look up all the NDC (national drug codes) in the 11K database, and reference the 176K database for each NDC,… then populate 7 fields in the 11K database with the corresponding code crosswalks from the 176K database.
the test database with 272 NDCs took a blink of an eye - as you said it would Paul
I should have timed it, but I can tell you that no sooner I would have pushed the button to start the timer, I would have had to stop the timer!
So the short answer: wicked fast and less than 3 seconds
and the best answer: a heckuva lot faster than copy/pasting/filling them in manually
The Automatic Matching Fields checkbox controls whether or not the matching fields will be used for data transfer when the join is performed. It does not affect the display of these fields in the dialog box.
If a field has had a data transfer formula set up, that formula will appear in black (not dim). It will be in black even if the formula is the same as the field name and the field name matches. The only way to get back to “dim” is to delete the formula.
Bottom line - there is nothing wrong with data transfer items that are not dim. That only means that these transfer items have been explicitly specified, not simply included automatically because the field names match.
Having imported many free online CMS databases (although not this one before) to PanX for various uses, I offer some generic suggestions. CMS databases tend to change periodically and the tasks for which they’re needed tend to repeat. But not repeat so often that you can recall all the steps that worked last time… So once you figure how to get the CMS data into PanX and how to therein do whatever is wished, automate it! PanX is fast, but your biggest time savings can come from not having to remember and manually do complex things each time. Write procedure(s) to do as much as you can figure how to commit to procedures. And include comments reminding you how to do the steps you weren’t able to put into procedures. Then when the task arises PanX does most of the work and you have notes on how to do the rest. The main limitation is sometimes rather than updating their data CMS reformats it . In which case you’ll need to adjust your procedures to compensate. That, and the amount you can automate, gets easier with practice.
PanX can time things for you; check Help. My slowest PanX task is to update my NPI (National Provider Identifier to non-medical types) number files. The entire national NPI file changes monthly, but couple updates a year suffice for me. The national file has about 7M records with 330 fields and comes as a zipped text file expanding to 7GB. I don’t have enough RAM to handle all that in one PanX db, at least not well, and wouldn’t recommend it. Although Jim’s offered precedent it could be done given enough RAM. Happily I only need a couple dozen fields of the records from the two states bordering me. I was able to code a routine that just took what I wanted from that huge file. And then added data with matching NPI codes from three smaller supplemental databases. Once I pointed the procedure at the 7GB file the whole process took 1:47:08 to finish, completely automated. So now if I want to search for every ENT specialist within 25 miles, or any other desired subset of bi-state NPI records, I can.
Hi JohnB.
thanks for the reply you have piqued my interest in your work.
the automation I will have to work on (as still a neophyte to the programming side of Pan), as now that I know how to join databases to get what I want, automating the process makes good sense, especially as I have several more dbases to join.
BUT the ability to have PanX time and perform routine update reviews is intriguing, and the program to pull the vital fields even moreso.
I have an NPI number but did not think of that as a good source for an upcoming project on physician quality. as an aside, what are you doing with the NPI data/
Npi#s for referring providers are needed for filing claims. I can get them and contact information via this if I can’t otherwise. I can also see what kind(s) or specialties an otherwise unknown provider is. And I’m able to compare, thru information exported by my 3rd party billing software, to check for invalid or expired numbers in that system. And I had fun coding to get it to work. More useful, although not Npi related, is having PanX import Medicare price limit files and pull out just those for the codes I actually use. Saves lots of time each year and by having PanX compare them to what billing software reports I can catch data entry typos.