I don’t think it is the same issue based on your description. You say “Every once in a while I’ll see something like this”, which makes it seem like the problem comes and goes. In this example, the problem was 100% reproducible.
But, if this is the issue, it would be pretty easy to check. Using the Formula Wizard, you could use the length( function to check the length. If it appears to be double what you think it should be, then it is the same problem. Gary’s fix should work in that case.
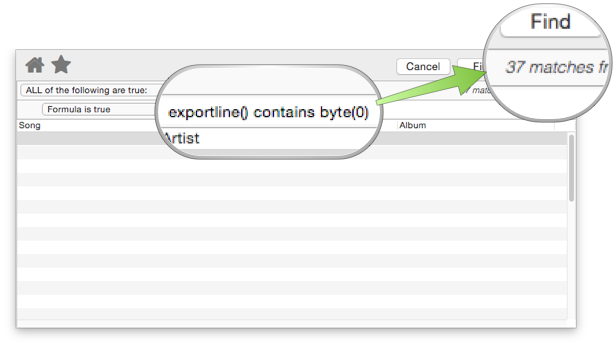
Here is another way to check. Open the FInd/Select dialog, then choose Formula is true. Then use the formula exportline() contains byte(0). The illustration below shows this being done with Rico’s Guitar Repertoire database. It turns out 37 records in this database (out of 43) contain UTF-16 data. So William, you could use this to check your database to see if this is the problem. If the database doesn’t contain any UTF-16 data, there will be 0 matches.
Being able to have UTF-8 & UTF-16 in Pano X is great but making effective use of it is perhaps the real key.
Has the the methodology for searches and such been resolved yet? i.e. I’d like to be able to enter a search for Soren and have all of Soren and Sören and Søren in the results.
An then too, there are things like Mahlestraße that needs to be found when searching for Mahlestrasse.
Yep, Gary’s fixed worked, and it turned out all the problematic records were imported from the same file into PX (i.e. not involving a conversion from P6). So this would seem to be the answer to issue #498, and also my description there was inaccurate in indicating that this was an intermittent problem. It must have seemed like that because it didn’t exist before I imported those records sometime this spring.
Just to be clear, Panorama X always stores text in UTF-8 format. But this is immaterial to you, since UTF-8, UTF-16, and UTF-32 are just variations on the same thing, and can be freely converted when necessary (for example when importing or exporting).
Has the the methodology for searches and such been resolved yet? i.e. I’d like to be able to enter a search for Soren and have all of Soren and Sören and Søren in the results.
An then too, there are things like Mahlestraße that needs to be found when searching for Mahlestrasse.
Other than the stripdiacritical( function, this issue has not been addressed.