When I go to Preferences and select “Relations” not all of the fields in the database are listed. What would cause this. I need the missing fields

I can’t really tell exactly what is going on from that screenshot. If you have fields with names that end in numbers, it may be treating those fields as line items.
You have activated “Automatic Matching Fields”. That works for fields with identical names in both databases, not if the field names are different.
The documentation says:
If the field names aren’t the same, you have to give Panorama a bit of help in making the connection. For example, perhaps data should be transferred from the Notes field in the Vendor database into the Memo database. The field names are different so this won’t happen automatically. To make this happen, drag the field name from the list of source database fields (on the right) into the list on the left, leaving it next to the field you want to transfer it into.
The text is so small I can’t read the field names. I was assuming he was saying that some of the fields weren’t listed in the dialog at all, but I can’t actually see if that is the case.
That seems to be the case. 2021Code is the last one listed, and that also seems to be the last one whose name doesn’t end with a number.
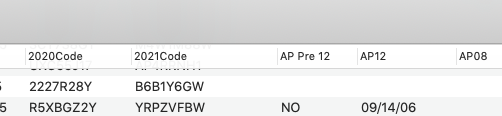
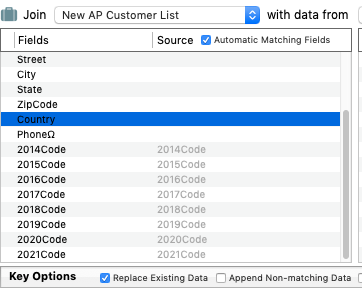
I have attached .png of the screenshot that should be openable in Preview. From what I have read, am I to gather that I should not have any fields end in a number unless it is a line item?

Well trying to attach a screenshot as a .png doesn’t seem to have worked. I’ll see what else I can come up with.
Your attachment didn’t work for me, the file is only 261 bytes and I can’t see anything. But I think we’ve hit on the answer – the problem is field names that end with a number. That can cause problems because some parts of Panorama interpret that as a line item field. If it’s reasonable to change the field names so that they don’t end with a number, that should solve the problem. I may be able to add a preference to this panel to exclude some field names as line items.

Well, I’ll think on the name change and come up with some name/title combo but it would be a shame not to be able to add a year designation to a field name.
Ok, thanks, actually I was able to expand that right here in the forum without even downloading it. So Panorama thinks all the fields that start with AP are line items. I’ve submitted this for future consideration.
Changing the names did solve the listing problem. I’ll change the DB. I am reworking it from an earlier DB that did not have that relations dialog. At least the reprogramming issues will be ameliorated by easier creation and maintenance of relations. 
Remember that in Panorama X you can change the field titles so that the data sheet will display AP2017, AP2018, etc. even if the field names are something different.
Yep, that was the plan. A better display name (Title) was already chosen, but I have to change some coding to reflect the name change.
Sam, you’ve probably already changed your database with different field names, but I have now changed the Relations panel to make it smarter about what it considers to be a line item field. It will only treat a field as a line item field if that field is part of a sequence starting with 1, for example Qty1, Qty2, Qty3, etc. If the sequence does not start with 1, for example FY18, FY19, FY20, FY21 then the fields are treated as ordinary fields. Here is a screen shot showing how this will work in the next version:

This change took quite a bit of work but I think this issue will probably come often enough that it is worth the trouble, especially since the Relation panel is I think going to be a very important feature in Panorama going forward.
Jim, though it is easier to looks for the specific suffix, “1”, it still seems like you also have to look for a second field with the same prefix and +1 increment; ie test1, test2. Given that, I wonder if it is really necessary to start the suffix at “1”, If a field had any numerical ending, and there was another field with the same alpha prefix and suffix +1, that would be a “sequence”.
Because the fields can be in any order, it seems the code would have to look at all of them. I don’t know if the code squirrels away any field with a numeric suffix and then revisit them if a suffix of “1” is found (to determine if there is a suffix2). So if there as any suffix(number) and suffix(number+1) that could be a line item without having to start with the number “1”.
Maybe that would create more confusion. Maybe it’s better to require “line items” to start at one so other sequences won’t be affected. I was just thinking of someone working with sequential product codes that could benefit from “line item” notation but though in +1 sequence, the product code suffix might not start at “1”.
Perhaps you only read my last post and didn’t go back to the original problem. @sam has sequential fields with numeric suffixes for different years, and he doesn’t want them treated as line items. The sequence doesn’t start with one. I think this is somewhat common, and that checking for an item sequence starting with 1 is a reasonable algorithm for differentiating line items from fields that happen to have a repeating suffix…
I have also seen cases where someone had sequential fields that DO start with 1 but aren’t supposed to be line items. But the line has to be drawn somewhere.
No, I read it. I just forgot  Too much time in a classroom with a teacher who like to remind us that a “sequence” doesn’t have to start at “1”.
Too much time in a classroom with a teacher who like to remind us that a “sequence” doesn’t have to start at “1”.
One vote for Jim’s original thought for a workaround in proposal #1120: an option to exclude certain root names from consideration of line items.
I pull a subset of data from a Fed database distributed as an 8GB cvs file. It has seven million records and 330 mostly empty fields, creatively named f1 thru f330. They are, mostly, not PanX’s concept of line item fields. Although their guide to the 330 fields’ contents shows slots for 15 versions of some data items and 50 versions of some others. Happily I need none of those. A procedure I run every few months parses out the records and fields I want over 2 hours. Its key field for relating with other databases the Feds call “f1”. I’d left their field names as is, adding Titles where helpful, in my prior coding.
I can hand code KEY and SOURCEKEY in Join statements to bypass the panel. That works with “f1”. I haven’t yet tried the same override with Selectrelated, on which Help recommends using the panel, but suspect it would work. I’m guessing all of the new 10.2 relational tricks can be done via procedures without the nifty panel interface, but perhaps I’m missing some exception.
The logical solution of renaming just “f1” I haven’t yet thought thru, but may be straightforward. If I’m reading Jim correctly I now wouldn’t need to rename the other ‘f#’ fields to avoid treating them as line items. If my import/parsing code really needs it to be named “f1” at some point, of which I’m yet unsure, I might end up changing the name of a ‘key’ field back and forth. Which a recent thread showed broke panel relationships pending another fix from Jim.
I can easily imagine some setting to override default line item presumption, as an additional path around the problem, but I can’t imagine the time, difficulty and unintended consequences involved with adding that. Where to draw the inevitable line only Jim can judge.
Yes, I think that will do what you want.
Renaming a field used in a relationship will always break the relationship – that’s not going to change. The only thing I plan to work on is to make it a bit easier to fix. It’s not impossible now, just more awkward than it should be. But when you rename a field any formulas, procedure code, forms and relationships that rely on that field name must be manually changed.