I want to replace a single field of my DB by importing a replacement field, either from text or from a Pano DB made from it. The relevant help file says I can do this by giving the import field the same name as the one to be replaced on the original database. Going on I learned how to select one of two possible options which end up like this:
The original field is replaced by the new one and all others are destroyed
My original work is not destroyed but the imported field is appended at the tail of the field instead of replacing it, making the operation perfectly useless.
You could do it by writing a program to bring in the data one cell at a time, but there is no built-in command to do this operation.
Your request implies that somehow you have a text file where the lines in the text file match up exactly with the existing rows in your database. In other words, the first row in the text file corresponds to the first row in the database, the second row in the text file with the second in the database, etc. That would be a very unusual situation, but it is the only way your request makes sense.
How are you getting this “replacement” data that exactly matches up with the existing data? If this is really the case, as I said it can be programmed, but I’d like to understand what is really going on before proposing a solution. Where did the original data come from? Where is the replacement data coming from? How is it that they match up row for row?
Thank you. And yes: you readily understood the only way my request makes sense. Let’s take 50 lines of Homer. Or 50 twitter messages of president Trump, if you prefer to step a tad down. No somebody provides you with translations those lines or messages, one into French, one into English, one into German. Would it be a very unusual situation to bring these into 4 columns, for easy comparison? I thought a moment about unequal field lengths myself. But I assumed that the programmer would just cut those rows which went beyond the number of rows in the importing file.
The Pan X Help describes importing of data records by appending to existing data or by replacing existing records. It is NOT about replacing fields (columns in the spreadsheet view).
I am wondering if the situation you mentioned is ideal for database use, but let’s think about your tweets example.
So I suggest you have your database open with the tweet collection in English, let’s say 50 records. You prepare your database and add new fields for the translations e.g. French and German.
You need a key field in both files that enables you to match the original tweet and the translation. This could be an additional ID number field in both files, or you simply set up your translation files in a two columns format: the original English text in the left column, the translation in the right column. Then the original tweet would be the key field.
Then you simply open the translation file as a separate database. In your original database, you select one of the empty translation columns and import the translation from the second file with the menu command Records > Morph … (using the lookup( function).
So you would be able to import a translation column into your database.
As it sounds like you will have a common column in the Panorama file as well as the Translation file (the original quote), you can have the incoming file be 2 fields, and then match on the original quote field.
This will also allow you to have ‘added to’ the number of records in the Panorama file while you are waiting for someone to do the translations to another language which will then later be brought in and matched up with the records that existed when you sent out your request to the translator.
So yes, I would say that it would be very, very unusual for someone to provide you with separate text files with these separate translations in the same order. But assuming this hypothetical situation, here is code that would replace the data in a given column. I’m assuming that the text file *french.txt" is in the same folder as the database, you would of course need to adjust this for your actual field and file names.
field French
let newcolumn = lftocr(fileload("french.txt"))
firstrecord
looparray newcolumn,cr(),newcell
«» = newcell
downrecord
stoploopif info("stopped")
endloop
Here is an alternate approach that would probably work faster.
field French
let newcolumn = lftocr(fileload("french.txt"))
formulafill nthline(newcolumn,seq())
Please note that I have not tested either of these programs, so they may have small syntax errors.
In general, if I wanted to add a new field containing data, I would export the contents of the database as an array, use the arraymerge( function to add in the incoming field and re-import the array to the database.
If the new field is to be inserted rather than added, you can export the database as two arrays and use the arraymerge( function twice.
Thank you.
Of course I could use a spreadsheet, or (as I often do) the table function in Nisus to solve the problem.
But Panorama’s “View” Window gives me far superior tools to display search results.
This said I don’t quite understand what you propose. I can’t see a "menu command Records > Morph” and I don’t know how exactly I should use the lookup( function). Would you explain to a novice?
Thanks for your help. The second macro works fine. It took about a second to fill about 1000 cells as desired.
The first macro might contain an error. It took about 2 minutes, but the cells were empty.
My mistake: The Morph command is in the Fields menu.
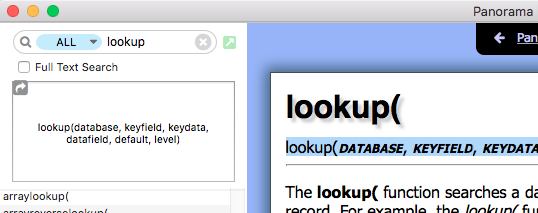
The command Morph… opens a dialog where you can use a formula to modify the contents of the active field. When you use a lookup( formula you can fetch data from a second (open) database.
That’s basically the same as to use code like this in a procedure:
field MyTranslation
formula fill lookup(DATABASE, KEYFIELD, KEYDATA, DATAFIELD, DEFAULT, LEVEL)
Functions like this are well documented in the Panorama X Help.
(Hint: Set the blue button in the search field to “All”.)
The advantage of this method: Since the lookup( function is looking for matching key fields in both databases, your original file and the translation file do not have to be in exact the same order.
I tried but it did not work. So sorry to come back once again.
I am in the field to which I want to retrieve data. So the 4 parameters lookup( needs all concern the open file from which to retrieve data, right? Then I I am concerned with:
1 database – is the database that will be searched.
Ok understood
2 keyfield – is the name of the field that you want to search in.
That’s an easy one: I have only one field
3 keydata – is the actual data that you want to search for.
Well: I want any data it finds in each keyfield. But how to express that in the lookup( formula
4 datafield – is the name of the field that you want to retrieve data from.
That’s an easy one: I have only one field
Could you kindly help me with nr. 3, or point out errors you can see from the above?
If you only have one field, Lookup( makes no sense. All you can do is search.
I am not certain what you want to do. Do you have a database with text in English, and another one with the same text in German, and another with the same text in French, and you want to combine them into one database with three fields, with the text in English, German, and French, respectively? The only way you are going to do this in any way that makes sense is if the text is in the same order in all three databases.
your original database “Original” with a column “Tweets” and at least one additional column for translation, let’s say “German”.
a second database “Translation” containing a column “originalTweet” and a second column “translatedTweet”.
In your original database, you click in the field “German” and invoke the menu command Fields > Morph …
From the popup menu you select “Start with formula”.